AMD-ov prvi 7-nanometarski GPU u ofenzivi na podatkovne centre


Uz 7-nanometarske procesore EPYC, AMD je na konferenciji u San Franciscu demonstrirao i novi akcelerator za strojno učenje, temeljen na 7-nanometarskoj inačici arhitekture Vega
U našoj prvoj vijesti povezanoj s AMD-ovom konferencijom Next Horizon koja je prošlog tjedna održana u San Franciscu mogli ste pročitati o impresivnim 64-jezgrenim procesorima kodnog imena Rome, temeljenih na kombinaciji 7-nanometarskog i 14-nanometarskog silicija i arhitekturi Zen 2. No, AMD je na istom mjestu demonstrirao i nove grafičke kartice namijenjene podatkovnim centrima – Radeon Instinct MI60 i MI50. Riječ je o prvim AMD-ovim grafičkim procesorima koji su izrađeni 7-nanometarskim proizvodnim procesom, prvim samostalnim GPU-ovima temeljenim na istom procesu te prvim GPU-ovima koji podržavaju PCI Express 4.0 sistemsko sučelje. Riječ je također o GPU-ovima koji nude ECC memoriju na svim razinama – od vanjske video memorije do svih razina interne cache memorije, te punu podršku za hardversku virtualizaciju.

Novi GPU-ovi temeljeni su na novoj i optimiziranoj varijanti arhitekture Vega, s optimizacijama usmjerenim na što bolje izvođenje softvera koji se izvodi u podatkovnim centrima visokih performansi, s posebnim naglaskom na strojno učenje i umjetnu inteligenciju. AMD s novim karticama cilja na Nvidijine Tesla V100 kartice, u odnosu na koje nudi slične performanse, barem prema internim mjerenjima koja su prikazana na konferenciji.


Točnije, AMD tvrdi da Instinct MI60 nudi 94% performansi Tesle V100 u Resnet-50 FP32 testu, 107% performansi u SGEMM FP32 testu i 101% performansi u DGEMM FP64 testu. Resnet-50 je test koji mjeri performanse pri treniranju neuralne mreže na hrpi fotografija dok SGEMM mjeri performanse u množenju matrica koje se sastoje od decimalnih vrijednosti s običnom 32-bitnom preciznošću dočim DGEMM mjeri to isto samo s dvostrukom odnosno 64-bitnom preciznošću. Doduše, treba naglasiti da prilikom mjerenja Resnet-50 performansi na Tesla karticama nisu korištene dedicirane Tensor jezgre koje računaju s kombiniranjem FP16 i FP32 preciznosti. U tom slučaju V100 nudi osjetno više performanse (oko 3,4 puta više) u odnosu na MI60.
Iako je činjenica da kombinirana preciznost u nekim slučajevima nije dovoljno dobra za treniranje neuronske mreže (FaceID aplikacija odnosno precizna identifikacija korisnika prema fotografiji lica koja traži preciznost višu od 99,9%), čini nam se da je ovdje više do izražaja došao motiv prikazati novi Radeon Instinct u što boljem svijetlu.

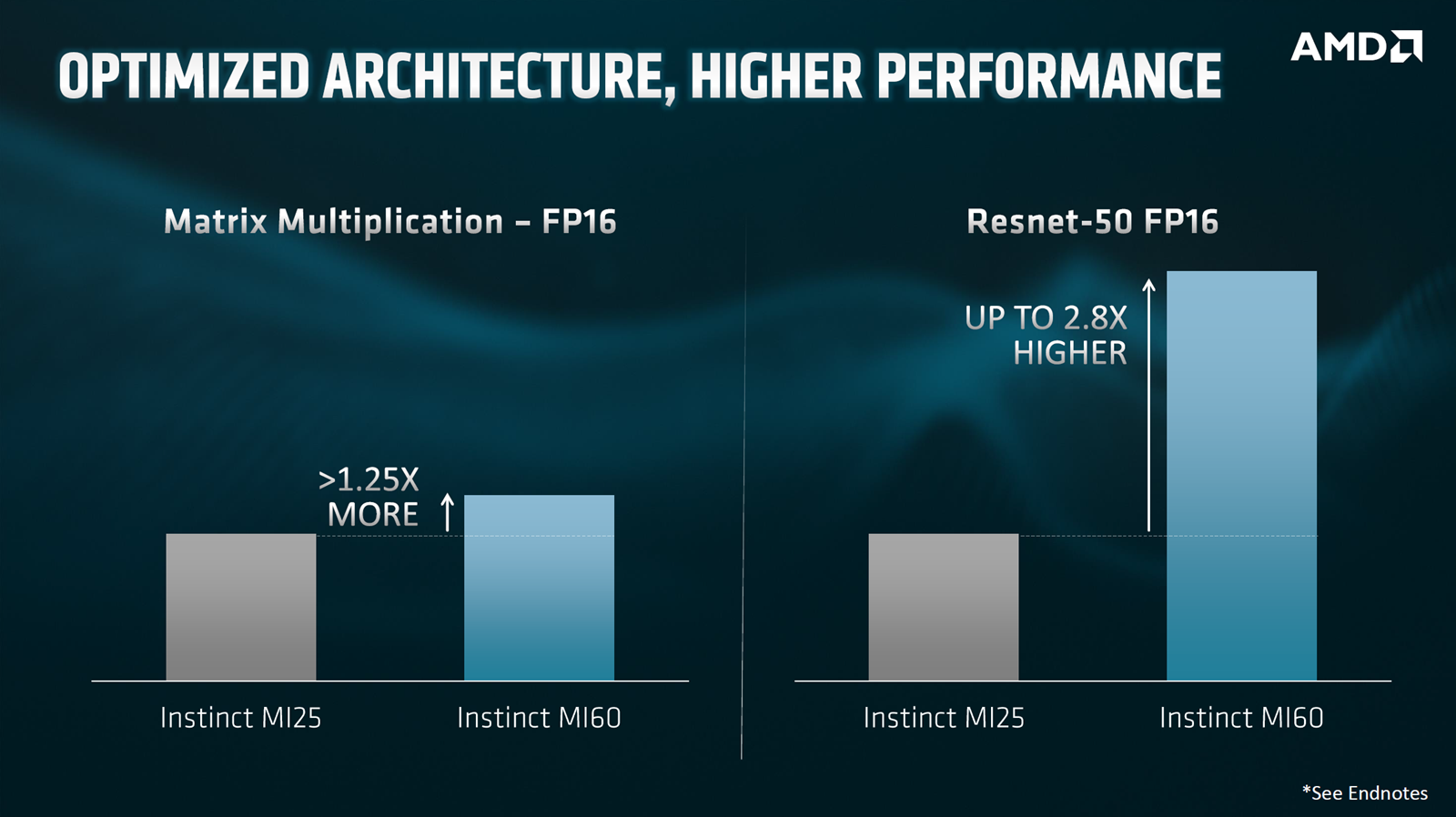
Naravno, MI60 u odnosu na stariji MI25 nudi osjetno bolje performanse u ovakvim specifičnim testovima. U najgorem slučaju porast performansi je 25%, u slučaju testova kod kojih MI60 ne nudi hardverske optimizacije u odnosu na stariju karticu. U drugim pak testovima, poput FP16 Resneta-50 (ubrzanje od 2,8 puta) ili pak DGEMM-a (ubrzanje od 8,8 puta) rast performansi je brutalno velik. Tu se opet ponavlja podatak iz prezentacije o novim 7-nanometarskim EPYC procesorima – da uz jednaku potrošnju 7-nanometarski GPU-ovi nude minimalno 25% bolje performanse, a uz zadržavanje jednakih performansi oko 50% nižu potrošnju. Drugim riječima, 7-nanometarski čipovi mogu ponuditi minimalno 25% viši taktu odnosu na 14-nanometarske.

U jednoj od prezentacija prikazani su MI25 i MI60 GPU-ovi jedan do drugog. Iako bi se dalo zaključiti da su čipovi prikazani u omjeru 1:1, to zapravo nije slučaj – MI60 osjetno je manji nego MI25. Navedeno je da novi proizvodni proces nudi do dva puta veću gustoću pakiranja tranzistora te da novi MI60 čip ima 13,2 milijarde tranzistora na površini od 331 mm2. Za usporedbu, stari MI25 izrađen 14-nanometarskim procesom ima 12,5 milijardi tranzistora na površini od 510 mm2 dočim Tesla V100 na 12-nanometarskom procesu ima 21,1 milijardu tranzistora na površini od čak 812 mm2. Kada se i ove brojke uzmu u računicu, Instinct MI60 nudi odlične performanse uz cijenu koja će vjerojatno biti osjetno niža u odnosu na Tesla V100. Ne samo zato što je MI60 jeftiniji za proizvodnju već i zato što AMD napada tržište u kojem trenutno suverena vlada Nvidija. Konkretna cijena nije otkrivena, no za ilustraciju - PCIe izvedbu Tesle V100 s 16 GB memorije na američkom je Amazonu potrebno izdvojiti 6.000 USD.
Činjenica je nova kartica i dalje temeljena na arhitekturi Vega, a koja sama predstavlja petu generaciju arhitekture GCN (Graphics Core Next), nažalost sa sobom nosi i problem visoke potrošnje. Iako MI60 ima znatno manje tranzistora u odnosu na Teslu V100, deklarirana potrošnja ima je jednaka – 300 vata. AMD se problema visoke potrošnje svojih kartica neće moći riješiti dok ne umirove GCN arhitekturu, a za to ćemo morati pričekati sljedeću godinu.
GPU-ovi kodnog imena Navi koji stižu do PC igrača početkom sljedeće godine neće biti temeljeni na novoj iteraciji GCN-a već na posve novoj arhitekturi koja će, nadajmo se, biti efikasnija u odnosu na GCN. U međuvremenu nas očekuje 12-nanometarsko osvježenje RX 500 serije u obliku Radeona RX 590 o kojem će više riječi biti u narednim tjednima.
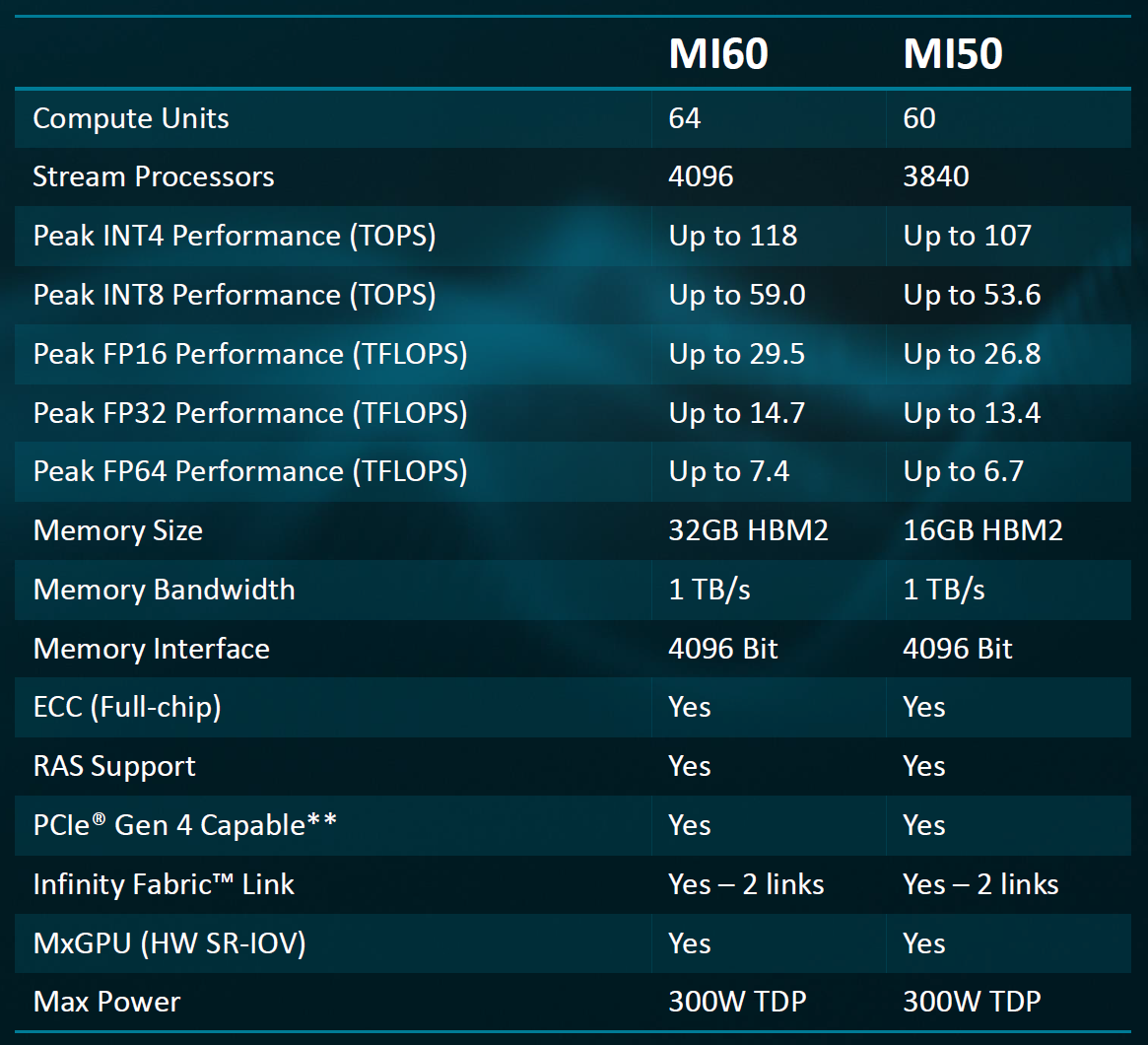

Iako je fokus bio na jačem Instinctu MI60, AMD je zapravo lansirao dvije kartice – MI60 i MI50. Slabiji model ima upola manje HBM2 memorije (16 umjesto 32 GB) te nešto slabije performanse na račun manjeg broja stream procesora – 3.840 naprema 4.096. Sve ostale karakteristike su jednake, uključujući podršku za više GPU-ova Infinity Fabric sučeljem.


Da, kao što smo i očekivali, AMD je Infinity Fabric odlučio izvući van samog (grafičkog) procesora te omogućio izravno povezivanje više GPU-ova preko ovog super-brzog sučelja. Konkretno, putem IF-a kartice mogu komunicirati brzinom od 200 GB/s što je trostruko brže od najnovijeg PCIe 4.0 sučelja. Doduše, to je i dalje znatno sporije od Nvidijinog NVLink sučelja koje ima jednaku svrhu, a nudi propusnost od 300 GB/s, no ovakvo sučelje je svakako dobro došlo budući da ga AMD-ove profesionalne kartice ranije nisu imale.













