Umjetna inteligencija sama povezuje audio i video bez pomoći ljudi
Istraživači Laboratorija za računalnu znanost i umjetnu inteligenciju CSAIL razvili su UI tehniku strojnog učenja koja uči identificirati i opisati radnju u video isječku


Ljudi promatraju svijet kombinirajući vid, sluh i razumijevanje jezika. Strojevi, s druge strane, tumače svijet putem podataka koje algoritmi mogu obraditi. Dakle, kad stroj "vidi" fotografiju, on je mora kodirati u podatke kako bi je klasificirao. Ovaj proces postaje složeniji kada podaci dolaze u više formata, poput videozapisa, audio isječaka i slika.
Strojno učenje
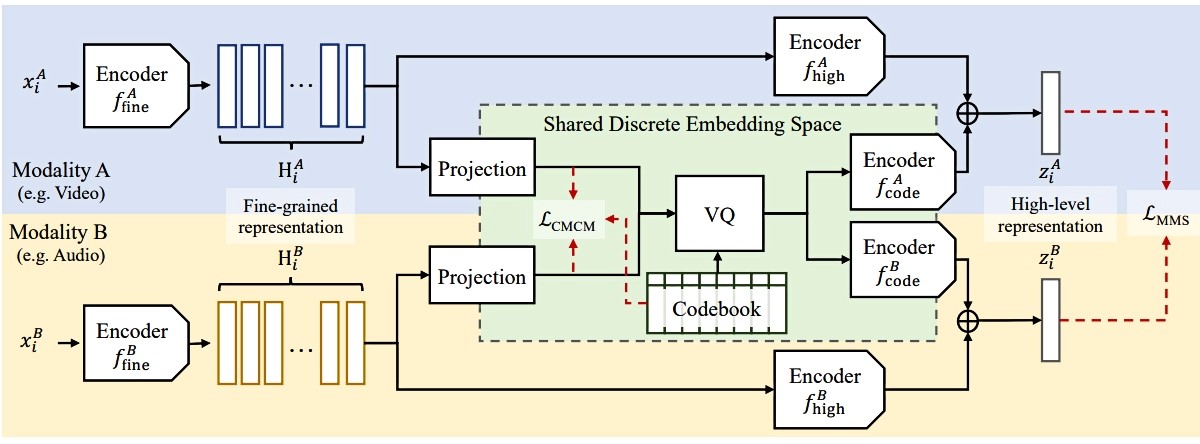
Glavni je izazov bio uskladiti različite modalitete. Ljudi s time nemaju problema; kad vidie auto i zatim čuju zvuk auta u prolazu, oni znaju da je to ista stvar. Ali u strojno učenju to nije baš tako jednostavno, objašnjavaju istraživači.
Istraživači Laboratorija za računalnu znanost i umjetnu inteligenciju (CSAIL) razvili su tehniku umjetne inteligencije koja uči povezivati audio i video.
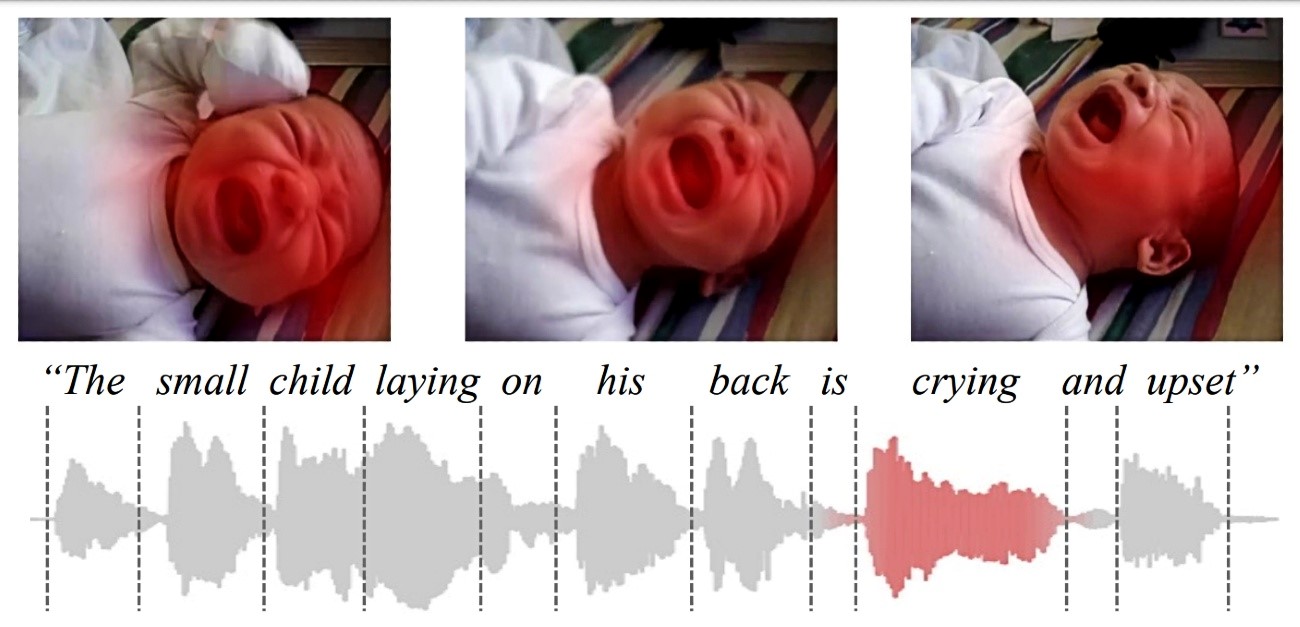
Na primjer, njihova metoda može naučiti da je plač bebe u videu povezan s izgovorenom riječi "plače" u audio isječku. Koristeći to znanje, ovaj model strojnog učenja može identificirati gdje se određena radnja odvija u videu i označiti je.
Ova tehnologija bi se jednog dana mogla upotrijebiti za pomoć robotima da uče o konceptima u svijetu kroz percepciju, kao što to čine ljudi, a istraživanje će biti predstavljeno na godišnjoj skupštini Udruge za računsku lingvistiku.
Klasifikacija i predviđanje
Istraživači su se usredotočili na učenje značajki, oblik strojnog učenja koji nastoji transformirati ulazne podatke kako bi se olakšala klasifikacija ili predviđanje.
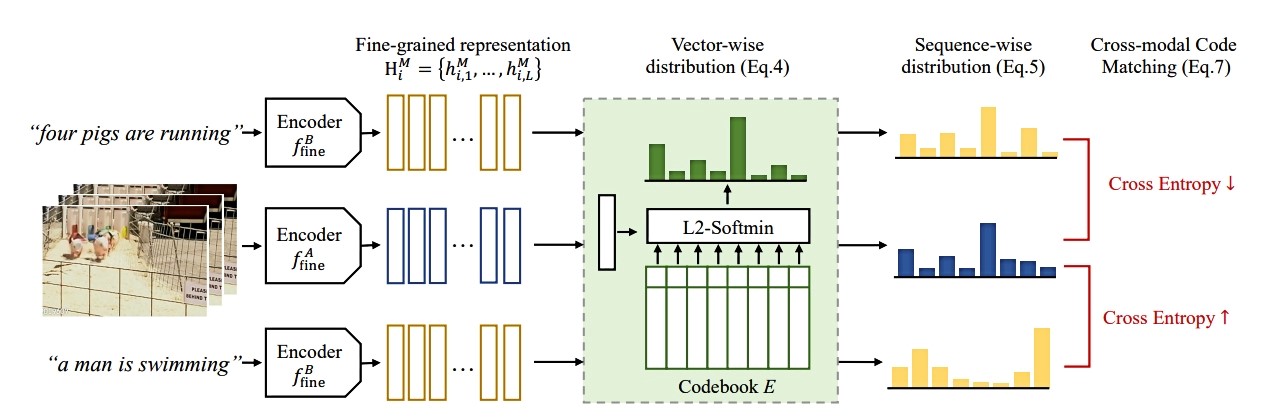
Ovaj model uzima sirove podatke poput videozapisa i odgovarajućih tekstova i kodira ih izdvajanjem značajki ili zapažanja o objektima i radnjama u videu. Potom te podatkovne točke preslikava u mrežu. Model grupira slične podatke zajedno kao pojedinačne točke u mreži. Svaka od ovih točaka podataka, ili vektora, predstavljena je pojedinačnom riječju.

Budući da je model mogao koristiti samo 1000 riječi za označavanje vektora, korisnik može lakše vidjeti koje je riječi stroj koristio da zaključi kako su video i izgovorene riječi slične. To bi moglo olakšati primjenu modela u stvarnim situacijama u kojima je od vitalnog značaja da korisnici razumiju kako donosi odluke.



























