KStreams: Što smo naučili tijekom produkcije Kafka Event Sourcinga?
Za pronalazak rješenja na izazove unutar KStreamsa morat ćete zamijeniti googlanje, StackOverflow i slično, solidnim razumijevanjem Kafke, KStreamsa i kreativnim rješavanjem problema

Kafka Streams jedan je od novijih dodataka na tržištu streaming frameworka. U integraciji s Kafkom, nudi niz mogućnosti za koje bi vam trebalo poprilično vremena kada biste se sami upustili u razvoj. Sâm Kafka izvrsno je učinkovit komad tehnologije, koji je već dokazao svoje mjesto u industriji, a Streams API vrlo je intuitivan za korištenje.
Međutim, Kafka Streams nije "srebrni metak". To je kompromis koji će vjerojatno riješiti vaš trenutačni problem, ali može uvesti i nove izazove kojih još niste svjesni, pogotovo jer neke od tih briga postaju očite tek nakon što ste prešli fazu izrade prototipa.
Opisat ću neke od izazova s kojima smo se mi u Spanovom timu za razvoj poslovnih rješenja suočili tijekom produkcije, i koji vam mogu pomoći donijeti odluku je li KStreams prava tehnologija za vaš "use case".
Krivulja učenja
Ako imate razvojni tim koji još nije upoznat s Kafkom, trebali biste očekivati da ćete naići na neke poteškoće dok se tim ne navikne na tehnologiju. U usporedbi s učenjem klasičnog web-frameworka, krivulja učenja mnogo je strmija.
S klasičnim popularnim nizom programskih jezika / popularnog frameworka / popularne baze podataka, problem koji imate vjerojatno je već riješen, i postoji više provjerenih rješenja – samo trebate pronaći najbolje za svoj "use case".
Međutim, KStreams potpuno je drugi par rukava. Za mnoge probleme morat ćete zamijeniti googlanje, StackOverflow i sl. solidnim razumijevanjem Kafke, KStreamsa i kreativnim rješavanjem problema.
Kao što će postati očito kasnije u ovom članku, da biste koristili Kafka Streams u bilo kojem netrivijalnom svojstvu, morate razumjeti i samu Kafku. To može zahtijevati početne napore za temeljito učenje dviju tehnologija.
Na vrijeme razmislite o svojoj strategiji migracije podataka
Kako se zahtjevi mijenjaju, možda ćete morati ažurirati poslovnu logiku svojih streamova, primjerice, dodavanjem još jednog svojstva (property) u postojeće evente. Ovisno o zahtjevima, to novo svojstvo možda će vam trebati i za već producirane evente, ili ćete možda morati popraviti grešku u onima već proizvedenima.
Ažuriranje poslovne logike streamova otvara nekoliko zanimljivih pitanja:
- Ako trebate napraviti recompute svog event-historyja da biste ponovno primijenili ažuriranu logiku, vaša će aplikacija prestati obrađivati nove dolazne podatke, dok prvo ponovno obrađuje stariju povijest. Je li to prihvatljivo za vaš sustav, ili su vam možda potrebne paralelne blue/green implementacije?
- Ako radite ponovnu obradu povijesnih podataka, to bi se moglo kaskadno odraziti i na downstream consumere, koji također rade rekalkulaciju povijesnih podataka. Hoće li ta ponovna reprodukcija stanja prouzročiti čudne nuspojave pri pozivima vanjskim sustavima? Može li vaša infrastruktura podnijeti skok opterećenja, ili želite selektivno preskočiti nezanimljive povijesne podatke?
- Koliko povijesnih podataka imate? Cijena takve promjene ne ovisi više samo o složenosti kôda, već i o količini ponovne obrade povijesnog stanja koju morate učiniti.
Ova pitanja odnose se i na druge event-sourced sustave, ne samo na Kafka streams. I na njih ćete morati sami odgovoriti.
Srećom, sve je rješivo ako planirate unaprijed. No, ako vas ovo iznenadi nakon što već imate desetak servisa u produkciji, to se može pretvoriti u pravi show-stopper.
Učinkovito jednom (unutar Kafke)
Oznaka značajke Exactly Once Processing Semantics na naslovnici KStreams može vam dati pogrešnu ideju ako ne uđete dublje u to kako to zapravo radi.
Iz naziva Exactly Once Processing možete pomisliti da se zapis uvijek obrađuje samo jednom u vašoj topologiji, bez obzira na sve. Međutim, to nije tako.
Da budemo precizniji, Kafka Streams nudi end-to-end efektivnu jednokratnu isporuku dobro osmišljenom upotrebom idempotencije i transakcija: stream s omogućenom Exactly Once semantikom može i dalje pokušavati i ponovno obrađivati evente više puta u slučaju greške, ali konačni rezultat koji se zapravo materijalizirao u Kafkinom izlaznom topicu izgleda kao da je doista obrađen točno jednom. Sve dok ostajete u Kafkinoj sferi i koristite samo idempotentne operacije u svojem streamu, ovo radi savršeno dobro.
Što se događa kada počnete uključivati sustave izvan Kafke?
Ako vaš stream sadrži, primjerice, HTTP API poziv vanjskom servisu, Kafka ne može dati nikakva transakcijska jamstva za taj sustav. Ako vaš stream naiđe na grešku, može pokušati ponoviti sve evente od zadnjeg commita – uključujući evente u kojima je vanjski HTTP poziv već uspio.
Kako bi se to riješilo, idealno je da vanjski servis podržava idempotentno ponašanje. Primjerice, sustav u kojem poziv jednostavno postavlja neko stanje, najvjerojatnije je već idempotentan – postavljanje istog stanja više puta ne bi trebalo prouzročiti probleme. Možda ćete, također, pronaći odgovarajući idempotentni ili transakcijski konektor za vaš ciljni sustav.
Pozivi u stilu RPC-a s nuspojavama (poput slanja obavijesti korisniku) zahtijevaju veću pozornost. Mogli biste, primjerice, izraditi jedinstveni ID za svaki događaj koji se propagira kroz sve transformacije i mapiranja vašeg streama, a koji zatim uključite u pozive prema vanjskom sustavu. Vanjski sustav mora provjeriti je li već obradio taj jedinstveni ID, i ispustiti duplikate. Druga moguća rješenja uključuju povećanje brojača, i tome slično.
Ako vanjski sustav nije idempotentan, morat ćete razmisliti o tome da implementirate najviše jednom, ili barem jednom, sigurnost pozivanja vanjskog sustava, bez obzira na to kako vaš tijek funkcionira unutar Kafke.
Bug KStreamsa?
Ovo nije bug KStreamsa – sinkronizacija stanja u distribuiranim sustavima temeljni je problem u dizajnu sustava. Međutim, Kafka Streams neće riješiti taj problem umjesto vas samo označavanjem excalty_once_checkboxa, a upravo to je, prema mojem mišljenju, pogrešno shvaćanje Kafka Streama kod nekih korisnika.
Threading model je jednostavan – veći dio vremena: nema asinkronog pozadinskog procesiranja u pozadini, niti procesuiranja u Batchu.
Kafka Streams sadrži single-threaded processing petlje koje obrađuju jedan po jedan zapis (pomislite, primjerice, NodeJS), što uvelike pojednostavljuje razumijevanje sustava na per-partition* razini.
(Napomena: *Particija je dio topica koja sadrži poruke garantiranim redoslijedom. Razdvajanje topica na više particija, koje paralelno obrađuje više consumera, jedan je od osnovnih mehanizama skaliranja Kafke.)
Kako funkcionira threading model kad vam treba desetak tisuća particija?
Ponekad ovaj jednostavni threading model može postati restriktivan – pogotovo jer ne postoji built-in podrška za blokiranje obrade petlje s long-running operacijama u vašem streamu.
Pretpostavimo da morate napraviti poziv vanjskom servisu koji nije Kafka, i kojem je potrebna jedna sekunda da odgovori, a vi imate pet particija u vašem event-topicu. Vaš throughput sada je ograničen na pet zapisa u sekundi.
Ako vam je potreban veći protok, jednostavno rješenje je više particija, što vam omogućuje pokretanje više threadova, koje se tada može paralelno blokirati. To čak može biti i dovoljno dobro za vaše zahtjeve, ako vam ne treba veliki throughput, ili ako vanjski servis ne blokira predugo.
Međutim, kada dođete do točke u kojoj će vam trebati deseci tisuća particija (ili mnogo više), možda ćete htjeti početi istraživati druge puteve.
Batching rute
Možete pokušati dodati podršku za asinkronu pozadinsku obradu u svoj stream, ili možete grupirati mnoge zapise u jedan blokirajući poziv – oboje morate izgraditi sami.
Krenuli smo batching rutama, jer jedan pojedinačni HTTP poziv po eventu ionako nije bio izvediv. Dodavanje podrške za micro-batching u Kafka Streams komponentu nije herkulovski zadatak, ali nije niti trivijalan – umalo je prouzročio kritičan problem u produkciji kada se instanca srušila, i nije se oporavila onako kako je predviđeno u našoj custom batching implementaciji.
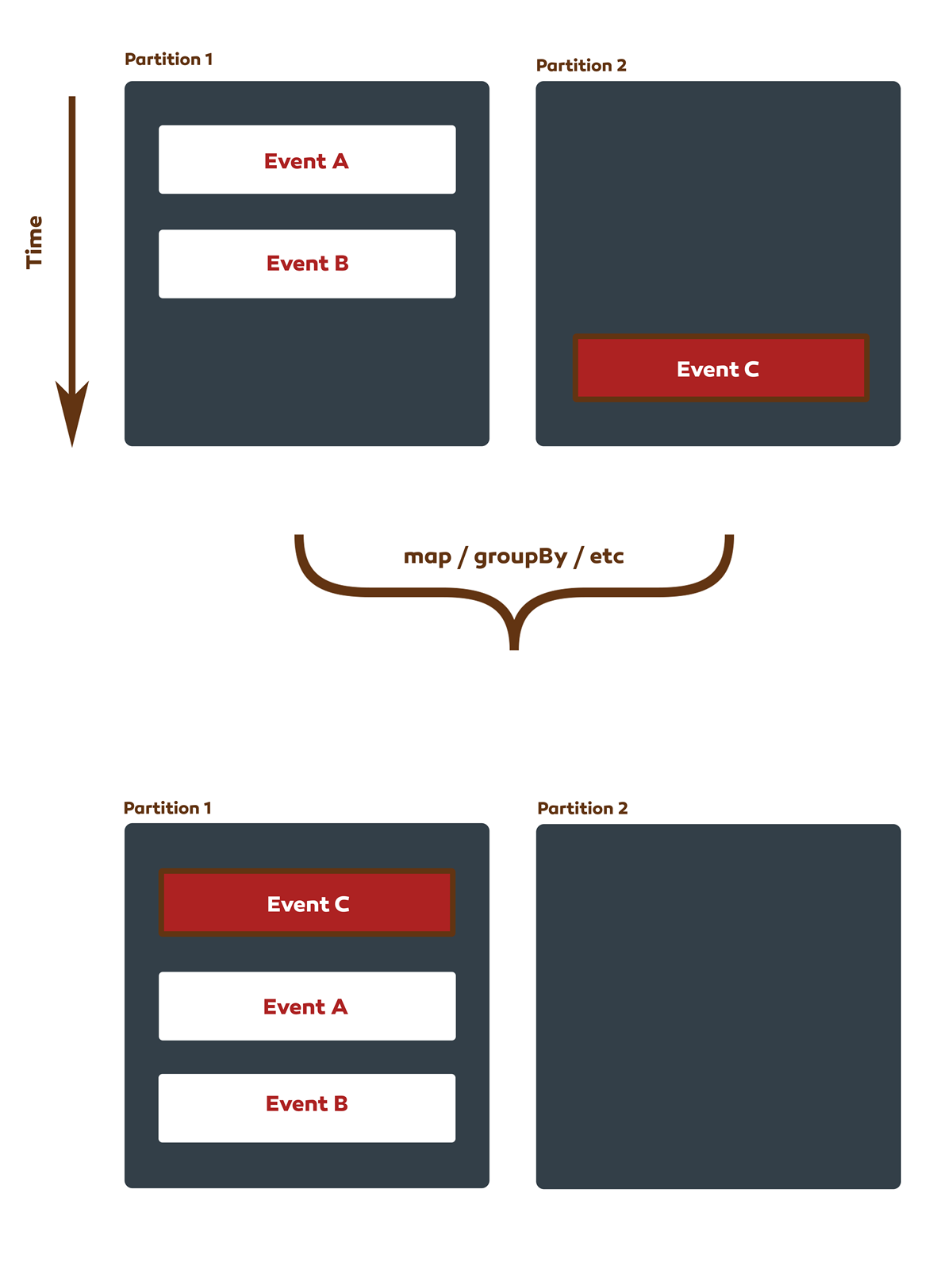
Obratite pozornost na redoslijed poruka
Jednostavno i bezopasno izgleda…
stream.map (record -> (newKey, someValue))
...ovo ima potencijal da proizvede nedosljedne rezultate ako je stream, primjerice, naknadno materijaliziran kao tablica.
Kao što je ranije spomenuto, concurrency model je jednostavan – ali to je i dalje concurrent sustav. Kada god promijenite ključ zapisa, taj se zapis može premjestiti s jedne particije na drugu, a zapisi s različitih ulaznih particija mogu se spojiti u istu izlaznu particiju. Za takav scenarij ne postoje jamstva za redoslijed; stariji event s particije 1 mogao bi se obraditi nakon novijeg eventa s particije 2.
Concurrency model
Rješenje – primjena logike koja čuva redoslijed evenata
Ovisno o vašem use caseu, možda ćete morati često mijenjati ključeve kada, primjerice, radite joining / merging / uspoređivanje podataka iz različitih izvora.
Svaki put kada to učinite, razmislite kako bi to moglo utjecati na redoslijed vaših evenata.
To je, naravno, rješivo, uglavnom implementacijom logike koja eksplicitno čuva (ili obnavlja) redoslijed evenata tijekom takve promjene ključa/particije.
Primjerice, ako vaši eventi sadrže neku vrstu time evenata, mogli biste jednostavno dropati evente (po particiji) koji sadrže opadajući timestamp u odnosu na prethodne evente (no tada ćete morati uzeti u obzir da vremena u distribuiranim sustavima nisu nužno savršeno sinkronizirana).
Ako niste svjesni jamstva za redoslijed koje pruža Kafka i interakcije Kafka Streamsa s tim jamstvima, lako možete izgraditi sustav koji proizvodi nedosljedne rezultate, a da to ne primijetite – što nas vraća na izvornu točku ovog posta: Kafka i KStreams vrlo su moćni, ali s velikom moći dolazi i velika odgovornost svakog programera u vašem timu.















