Ferovac u ekipi znanstvenika koji strojeve uče da nas čuju


Zoran Tiganj, docent na Sveučilištu Indiana Bloomington, pomogao je američkim istraživačima da osmisle alat za dubinsko učenje koji razumije riječi izgovorene različitim brzinama od onih na kojima je trenirana mreža
Kognitivni znanstvenik sa Sveučilišta u Virginiji, Per Sederberg ima zabavan eksperiment koji možete isprobati kod kuće. Izvadite pametni telefon i pomoću glasovnog asistenta poput onog za Googleovu tražilicu izgovorite riječ "octopus" što sporije možete. Vaš će uređaj teško ponoviti ono što ste upravo rekli. Mogao bi pružiti besmislen odgovor ili odgovoriti nešto kao "toe pus".
Tempo nije važan
Stvar je u tome, kaže Sederberg, kad je riječ o primanju slušnih signala, trenutna umjetna inteligencija, unatoč svoj računalnoj snazi kojom su je obdarili teškaši kao što su Google, Deep Mind, IBM i Microsoft, ostaje pomalo nagluha. Ishodi mogu varirati od komičnih i blago frustrirajućih do potpuno nerazumljivih za one koji imaju problema s govorom.

No, koristeći nedavna otkrića u neuroznanosti kao model, istraživači su osmislili način na koji će postojeće UI neuronske mreže pretvoriti u tehnologiju koja nas doista može čuti, bez obzira kojim tempom govorimo.
Veliki potencijal SITHCona
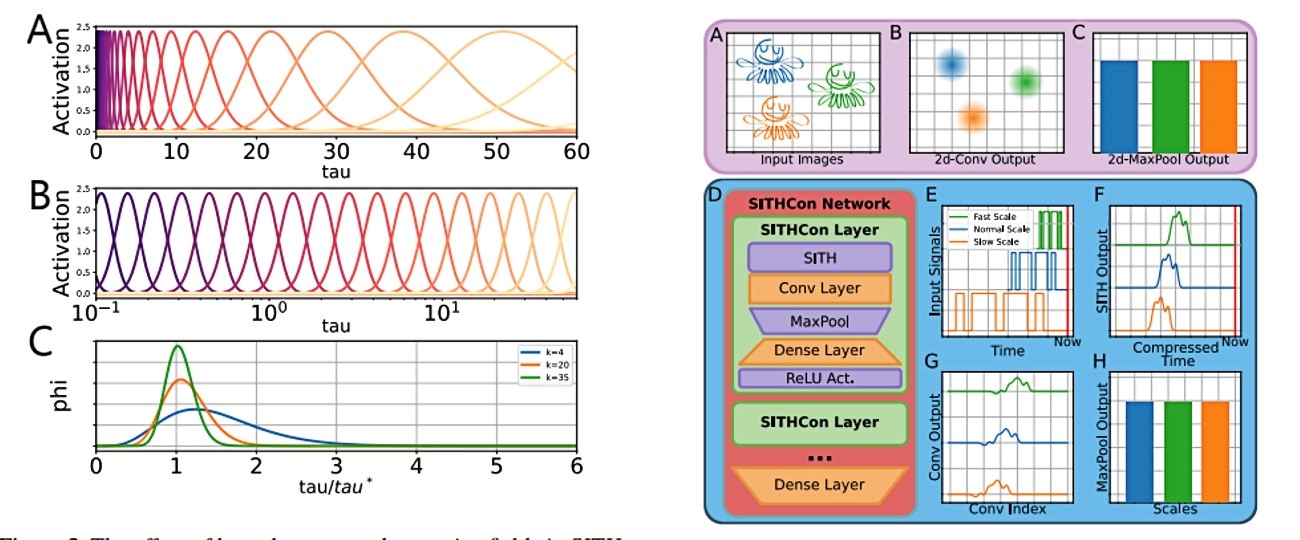
Ovaj alat za dubinsko učenje zove se SITHCon i generalizacijom unosa može razumjeti riječi izgovorene različitim brzinama od onih na kojima je trenirana mreža.
SITHCon ne mijenja samo iskustvo krajnjeg korisnika; on ima potencijal promijeniti i način na koji umjetne neuronske mreže "razmišljaju", omogućujući im učinkovitiju obradu informacija. A to bi pak moglo promijeniti sve u industriji koja neprestano želi poboljšati sposobnost obrade, minimizirati pohranu podataka i smanjiti golemi ugljični otisak umjetne inteligencije.
Jedan model kao pet automobila
Danas se u svijetu govori više od 7000 jezika. Varijacije nastaju s naglascima i dijalektima, dubljim ili višim glasovima i bržim ili sporijim govorom. Kako konkurenti stvaraju bolje proizvode, na svakom koraku računalo mora obrađivati informacije.

A to ima stvarne posljedice za okoliš. Studija 2019. godine pokazala je da su emisije ugljičnog dioksida iz energije potrebne za obuku jednog velikog modela dubokog učenja jednake otisku pet automobila. A otad su skupovi podataka i neuronske mreže samo nastavili rasti.
Pomoć ferovca
Revolucionarno istraživanje, predstavljeno na Međunarodnoj konferenciji o strojnom učenju ICML u Baltimoreu, kulminacija je Sederbergovog rada koji je prije pet godina s kolegama među kojima je i svojedobni zagrebački student, ferovac Zoran Tiganj, danas docent na Sveučilištu Indiana Bloomington, započeo izradu i testiranje modela.
Algoritam ima oblik kompresije koji se može raspakirati po potrebi, otprilike onako kako zip datoteka na računalu komprimira i pohranjuje velike datoteke. Stroj samo pohranjuje "memoriju" zvuka u razlučivosti koja će kasnije biti korisna, čime se štedi prostor za pohranu.
Proces obuke
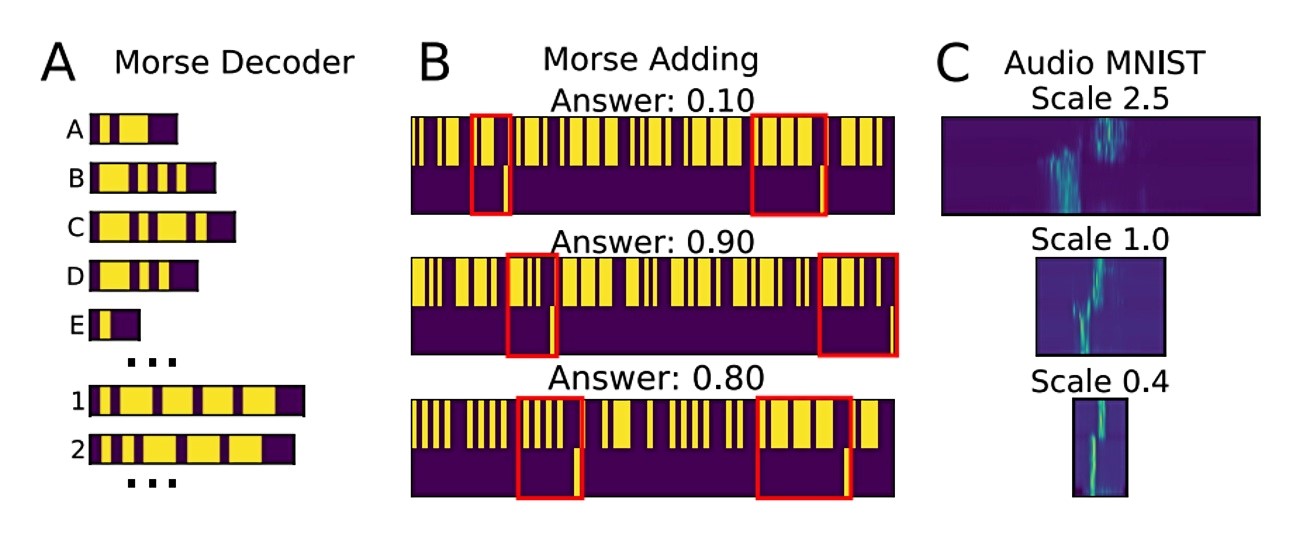
Obuka umjetne inteligencije za SITHCon uspoređena je s postojećim resursom, "vremenskom konvolucijskom mrežom", besplatno dostupnom istraživačima. Proces je započeo osnovnim jezikom, Morseovom abecedom koja koristi duge i kratke nizove zvukova za predstavljanje točaka i crtica, i napredovao do open-source skupa govornika engleskog jezika koji su izgovarali brojeve od 1 do 9. Daljnje usavršavanje nije bilo potrebno jer se umjetna inteligencija više nije dala prevariti nakon što je prepoznala komunikaciju pri jednoj brzini.
Istraživači su odlučili kod učiniti dostupnim, i to besplatno, a informacije bi se trebale prilagoditi bilo kojoj neuronskoj mreži koja prevodi glas.
"Dodirnuli smo temeljni način na koji mozak obrađuje informacije, kombinirajući snagu i učinkovitost, a tek smo zagrebali po površini onoga što ovi modeli umjetne inteligencije mogu," kaže Sederberg koji želi vjerovati da će se umjetnoj inteligenciji koja bolje čuje pristupiti etički, kao što bi u teoriji trebala biti sva tehnologija.








