Na Stanfordu Siri i Alexu podučavaju kada trebaju govoriti, a kada šutjeti
Predviđanje početnih točaka na temelju intonacije glasa umjesto otkrivanja tišine moglo bi dovesti do sljedeće generacije razgovornih agenata


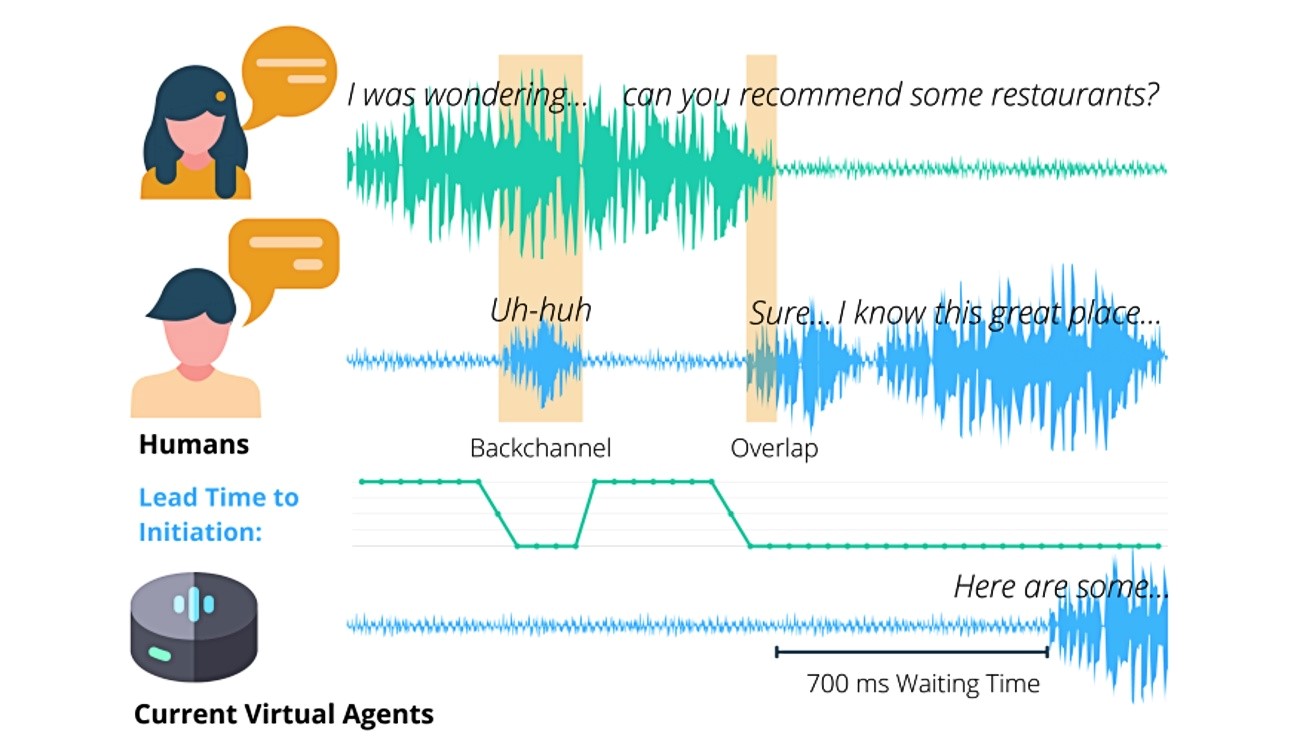
Uz vokalne obrasce poput visine glasa ili intonacije, trenuci tišine koji se javljaju unutar razgovora neki su od ključnih signala koje ljudi koriste u dijalozima. Čovjek čovjeku obično daje trenutak vremena za razmišljanje; govorni pomoćnici pak svaku šutnju tumače kao prekid razgovora i priliku da preuzmu inicijativu. U nedostatku boljeg razumijevanja signala, razgovorni agenti poput Sirija, Alexe i Google Homea često vode neumjerene, neprirodne razgovore.
Kako bi potakli stvaranje prirodnijeg tijeka razgovora, djelatnici Stanfordovog instituta za umjetnu inteligenciju usmjerenu na čovjeka (HAI) osmislili su način na koji će se razgovorni agent ponašati sličnije onome kako ljudi razgovaraju u stvarnom životu.
Detekcija tišine
Većina sustava za prepoznavanje govora prvo pretvaraju govor korisnika u tekst koji razgovorni agent obrađuje i potom generira tekstualni odgovor. Ovaj tekstualni odgovor se zatim pretvara u govor, što je izlaz koji čujemo kad Alexa odgovori na naš zahtjev.
Iako je tehnologija napredovala, činjenica je da se u ovom procesu gube nijanse verbalnog razgovora, a jezični povratni kanali koje ljudi koriste u razgovoru nestaju. Trenutačni agenti koriste detekciju tišine kako bi odredili kad je njihov red da govore, obično nakon 700 do 1000 milisekundi. Ljudi su puno brži od toga, obično reagiraju unutar 200 milisekundi, otkrivaju istraživači.
Kontinuirana analiza
Problem, kažu, nije samo u ljudskom razgovoru nego i u korisničkom sučelju. Ljudima je ugodno razgovarati s drugim ljudima i te karakteristike oni pokušavaju unijeti i u svoje razgovore s razgovornim agentima.

Ali kada te karakteristike nisu podržane, to postaje problem interakcije koji dovodi do zabune, upozoravaju Stanfordovi istraživači koji su odlučili reformulirati model za kontinuiranu analizu glasovnog unosa kako bi bio što sličniji onome što ljudi rade u stvarnom životu.
Najefikasnija kombinacija
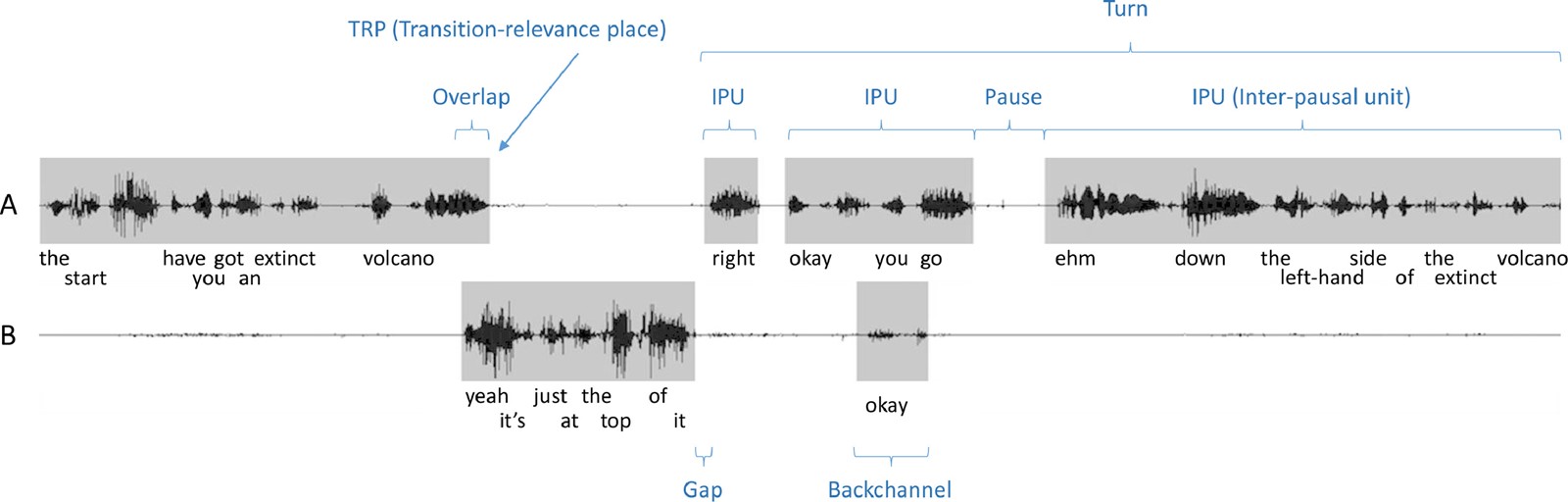
Istraživači su razmotrili dvije faze: govor i šutnju kako bi pokušali predvidjeti tok razgovora na temelju promjena intonacije. Pritom su koristili kombinaciju umjetne inteligencije otvorenog koda GPT-2 (Generative Pre-Training Transformer 2) za značajke riječi i wav2vec za prozodiju, značajke jezika koje utječu na stvaranje ritma i akustičnih efekata, s modelom Gaussovih mješavina (GMM).
Ova kombinacija modela pokazala se najučinkovitijom, lako nadmašujući trenutne modele temeljene na šutnji. Rezultat je model strojnog učenja koji kontinuirano predviđa i uvijek pazi je li došao red na agenta.
Glasovni pomoćnik 2.0
Model uzima u obzir intonaciju i druge prozodijske značajke iz govora i nudi uvid u korisnikov odgovor na određenu izjavu agenta. To je, vjeruju na Stanfordu, putokaz za buduće glasovne pomoćnike koji neće samo pretvarati tekst u govor i automatski prepoznavati govor s detekcijom pauze nego će u obzir uzimati i razne nijanse glasa.



















