DarkBERT: alat za borbu protiv kibernetičkog kriminala
Istraživači iz Južne Koreje razvili su novi LLM treniran isključivo na Dark webu


Nedavna istraživanja pokazala su da postoje jasne razlike u jeziku koji se koristi na Dark webu u usporedbi s jezikom Surface weba koji se može pretraživati standardnim tražilicama. Južnokorejski istraživači ovih su dana poduzeli korak bez presedana u razvoju i treniranju umjetne inteligencije na Dark webu i predstavili jezični model obučen na podacima mračnog weba.
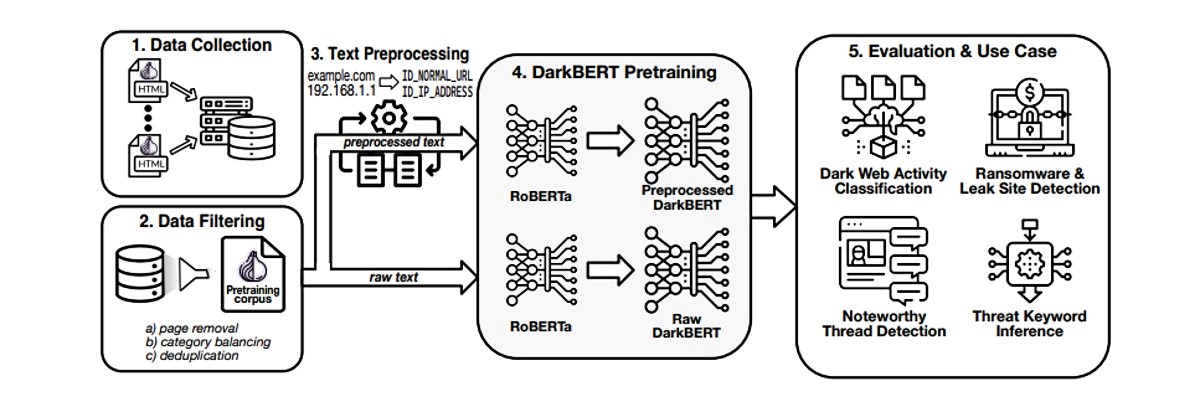
Umjetna inteligencija nazvana DarkBERT pokrenuta je kako bi pretraživala i indeksirala ono što je mogla pronaći kako bi se rasvijetlili načini borbe protiv kibernetičkog kriminala.
Vatrom protiv vatre
Dark Web koristi složene sustave koji maskiraju IP adrese svojih korisnika, a pristup zahtijeva specijalizirani softver, od kojih je najpopularniji Tor koji dnevno koristi otprilike 2,5 milijuna pretraživača mračne strane interneta. Porastom programa za obradu prirodnog jezika kao što je ChatGPT, takva se tehnologija sve više koristi kao nova vrsta kibernetičkog kriminala.
Razvijajući umjetnu inteligenciju koja se protiv vatre može boriti vatrom, istraživači su željeli otkriti kako im u tome mogu pomoći veliki jezični modeli (LLM). Rezultat južnokorejskog istraživanja je zasad nerecenzirani rad, objavljen na arXiv.org. Oni su svoj model povezali s mrežom Tor i prikupili neobrađene podatke za izradu baze podataka.
Mogućnosti DarkBERTa
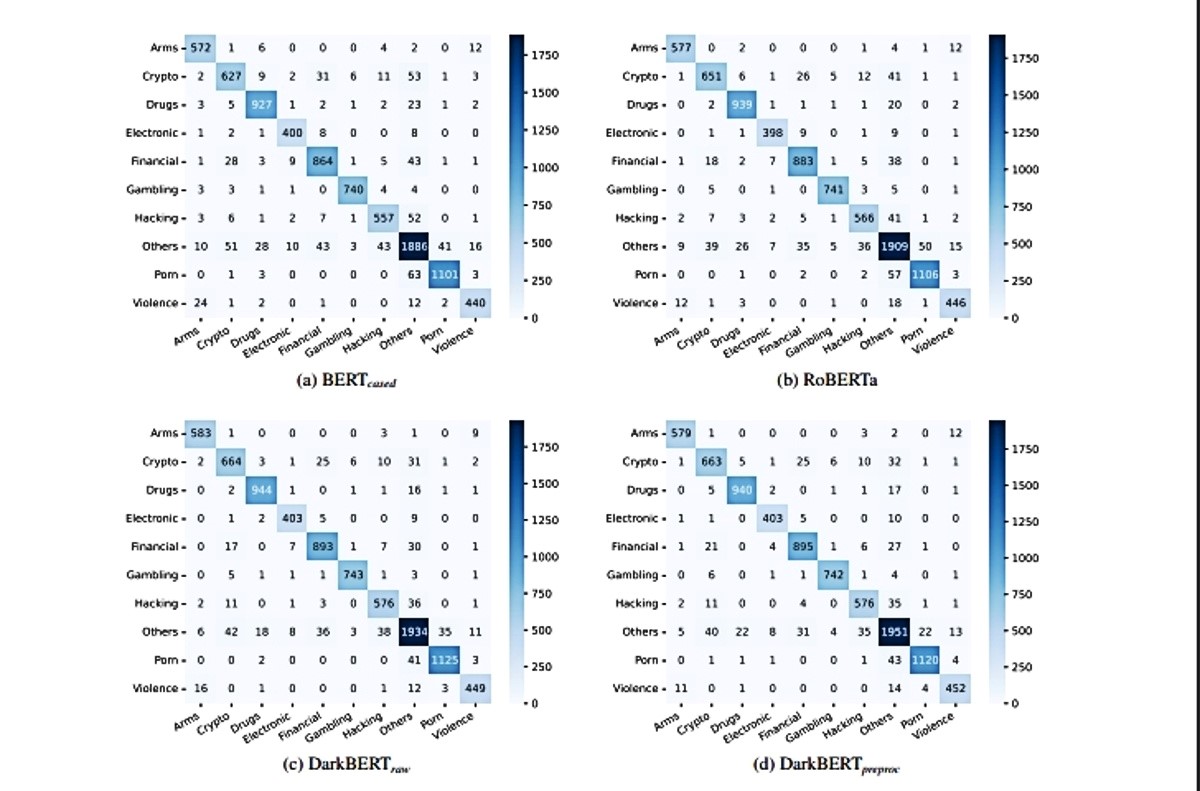
Objavljeni podaci ukazuju da je njihov LLM bio je daleko bolji u razumijevanju Dark weba od drugih modela obučenih za obavljanje sličnih zadataka, uključujući RoBERTa, koji su Facebookovi istraživači osmislili još 2019. kako bi "predvidio namjerno skrivene dijelove teksta unutar inače neoznačenog jezika".
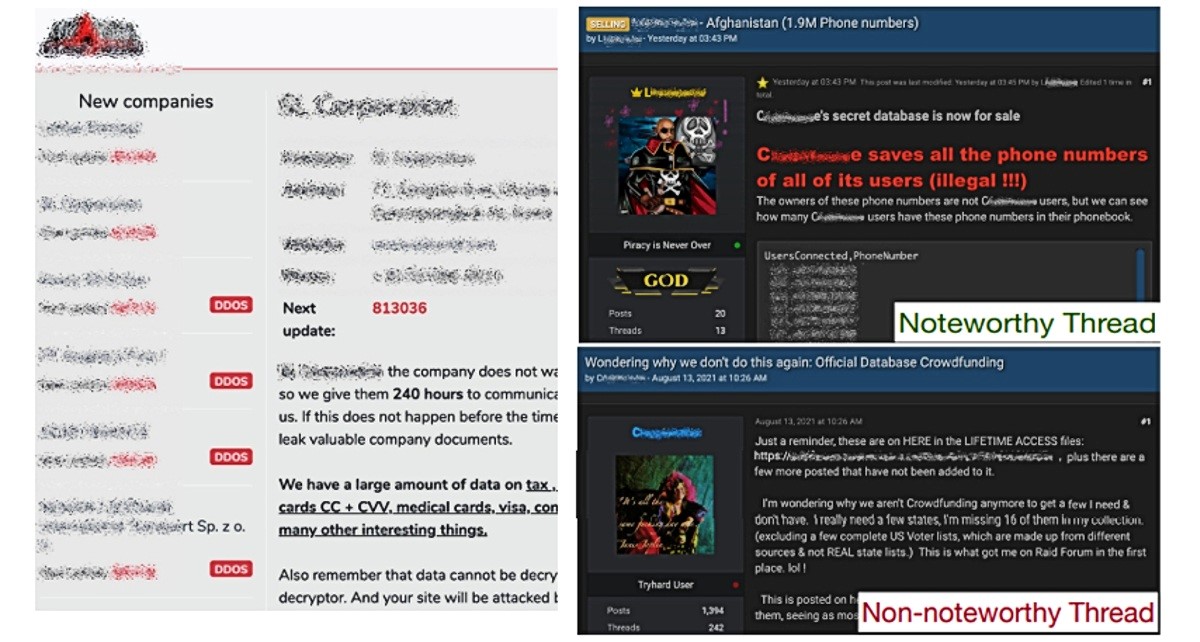
Južnokorejski istraživači tvrde kako njihov model ima potencijal u promicanju kibernetičke sigurnosti, uključujući identificiranje stranica koje prodaju ransomware ili objavljuju povjerljive podatke. Uz to, DarkBERT može pretraživati brojne forume Dark weba koji se svakodnevno ažuriraju i paziti na bilo kakvu ilegalnu razmjenu informacija.

























