UI je pametnija nego što smo mislili: računala razumiju složene riječi i koncepte
Istraživači su razvili tehniku "semantičke projekcije" i proučili skupine od 52 riječi kako bi vidjeli može li sustav naučiti razvrstavati značenja.


Značenja riječi već su dugo predmet istraživanja. Da bi shvatio njihovo značenje, ljudski um mora sortirati kroz složenu mrežu fleksibilnih, detaljnih informacija. A sada je noviji problem sa značenjem riječi izašao na vidjelo. Istraživači naime ispituju hoće li strojevi s umjetnom inteligencijom moći oponašati ljudske misaone procese i na sličan način razumjeti riječi. Istraživači s UCLA, MIT i Nacionalnog instituta za zdravlje upravo objavili studiju koja odgovara na to pitanje.
Čitanje materijala na internetu
Studija, objavljena u časopisu Nature Human Behaviour, pokazuje da sustavi umjetne inteligencije doista mogu uhvatiti vrlo složena značenja riječi. Istraživači su također pronašli jednostavnu metodu za dobivanje pristupa ovim sofisticiranim informacijama. Otkrili su da UI sustav koji su promatrali predstavlja značenja riječi na način koji je vrlo sličan ljudskoj prosudbi.
Sustav umjetne inteligencije koji su istražili autori naširoko je korišten za analizu značenja riječi tijekom posljednjeg desetljeća. Dohvaća značenja riječi "čitanjem" ogromnih količina materijala na internetu koji sadrži desetke milijardi riječi.
Kad se riječi često pojavljuju zajedno, na primjer "stol" i "stolica", sustav uči da su njihova značenja povezana. A ako se parovi riječi vrlo rijetko pojavljuju zajedno, poput "stola" i "planeta", ono uči da imaju vrlo različita značenja.
Zdrav razum
Autori studije istražili su što sustav zna o riječima koje uči i kakvu vrstu "zdravog razuma" ima. Činilo se da sustav ima veliko ograničenje: svake dvije riječi imaju samo jednu numeričku vrijednost koja predstavlja koliko su slične. Nasuprot tome, ljudsko znanje je mnogo detaljnije i složenije.
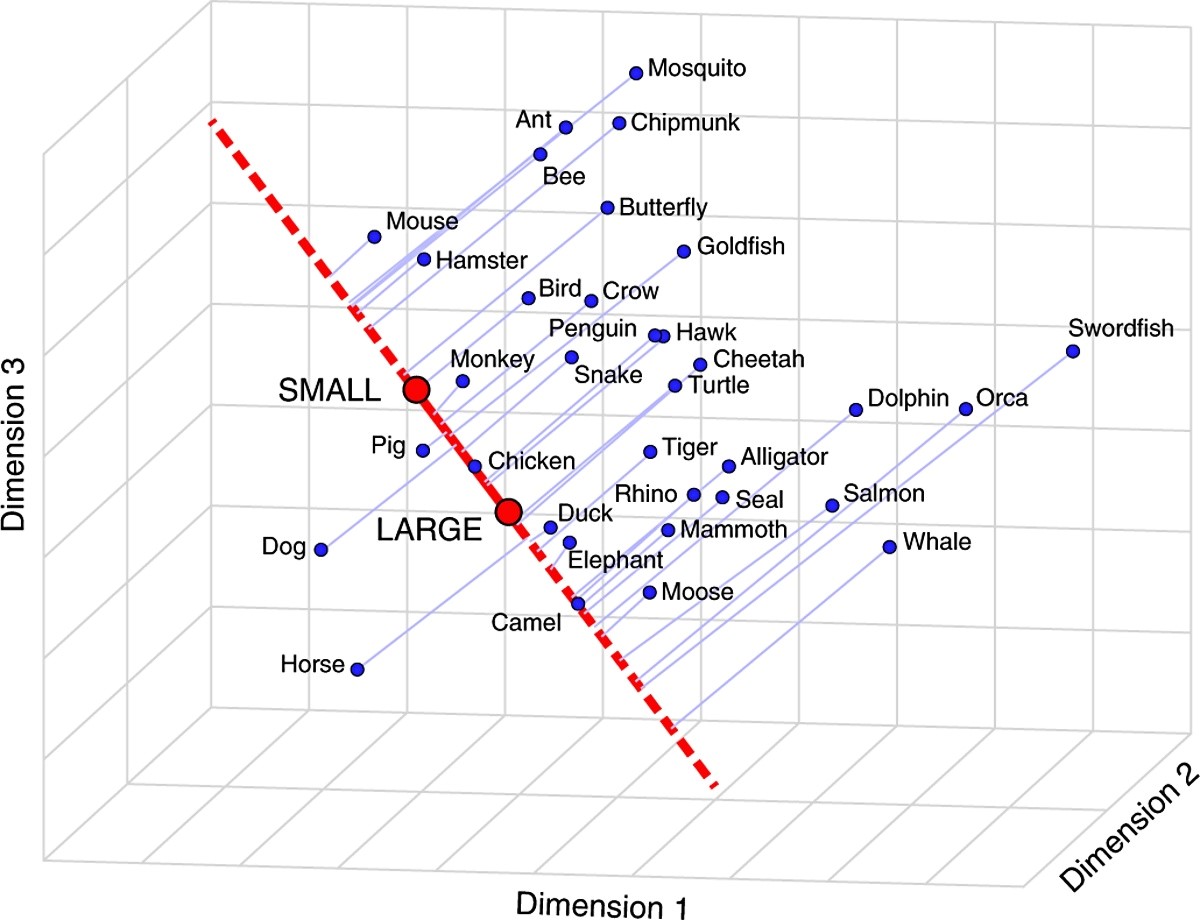
Istraživači su za primjer uzeli naše znanje o dupinima i aligatorima. Kad to dvoje usporedimo na ljestvici veličine, oni su relativno slični. Po svojoj inteligenciji oni su nešto drugačiji. A što se tiče opasnosti koju nam predstavljaju, jako se razlikuju. Dakle, značenje riječi ovisi o kontekstu.
Poput ljudske intuicije
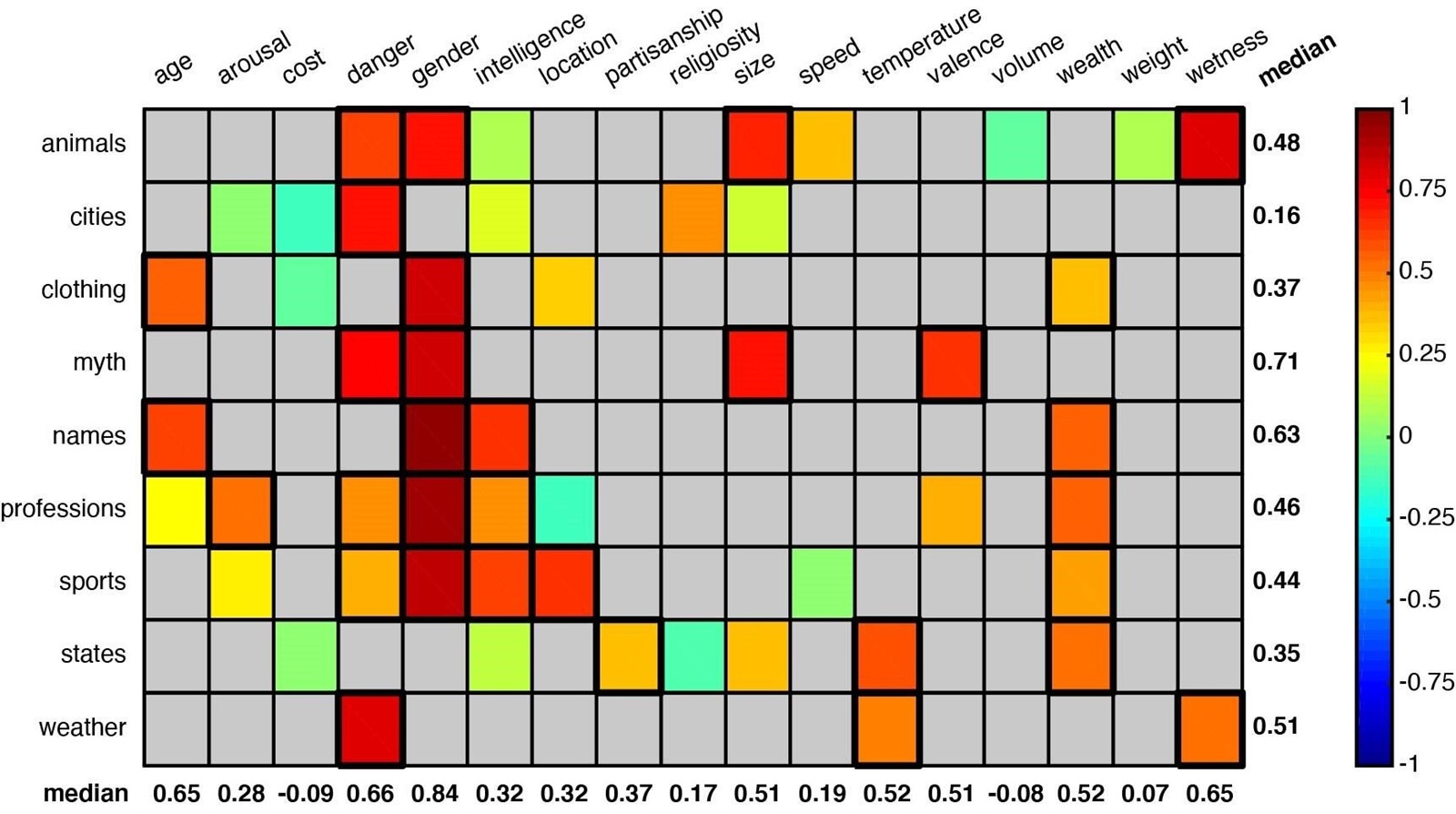
Autori su se zapitali poznaje li sustav te suptilne razlike; je li njegova ideja sličnosti fleksibilna kao i kod ljudi? Kako bi to otkrili, razvili su tehniku "semantičke projekcije" i proučavali skupine od 52 riječi kako bi vidjeli može li sustav naučiti razvrstavati značenja - poput prosuđivanja životinja prema njihovoj veličini ili koliko su opasne za ljude. Našlo se tu mjesta i za pojmove vezane uz odjeću, zanimanja, sport, mitološka bića i imena. Svakoj kategoriji dodijeljeno je više konteksta ili dimenzija, od veličine i opasnosti, preko inteligencije, do dobi i brzine.

Metoda se pokazala vrlo sličnom ljudskoj intuiciji. Sustav je naučio uočiti da su imena "Betty" i "George" slična u smislu da su relativno "stara", ali da predstavljaju različite spolove. I da su "dizanje utega" i "mačevanje" slični po tome što se oboje obično odvijaju u zatvorenom prostoru, ali se razlikuju po tome koliko inteligencije zahtijevaju.
“Ispostavilo se da je ovaj sustav strojnog učenja mnogo pametniji nego što smo mislili; sadrži vrlo složene oblike znanja, a to je znanje organizirano u vrlo intuitivnu strukturu. Samo praćenjem koje se riječi pojavljuju jedna uz drugu u jeziku, možete naučiti mnogo o svijetu", objašnjavaju istraživači.





























