Umjetna inteligencija uči obrasce prirodnih jezika
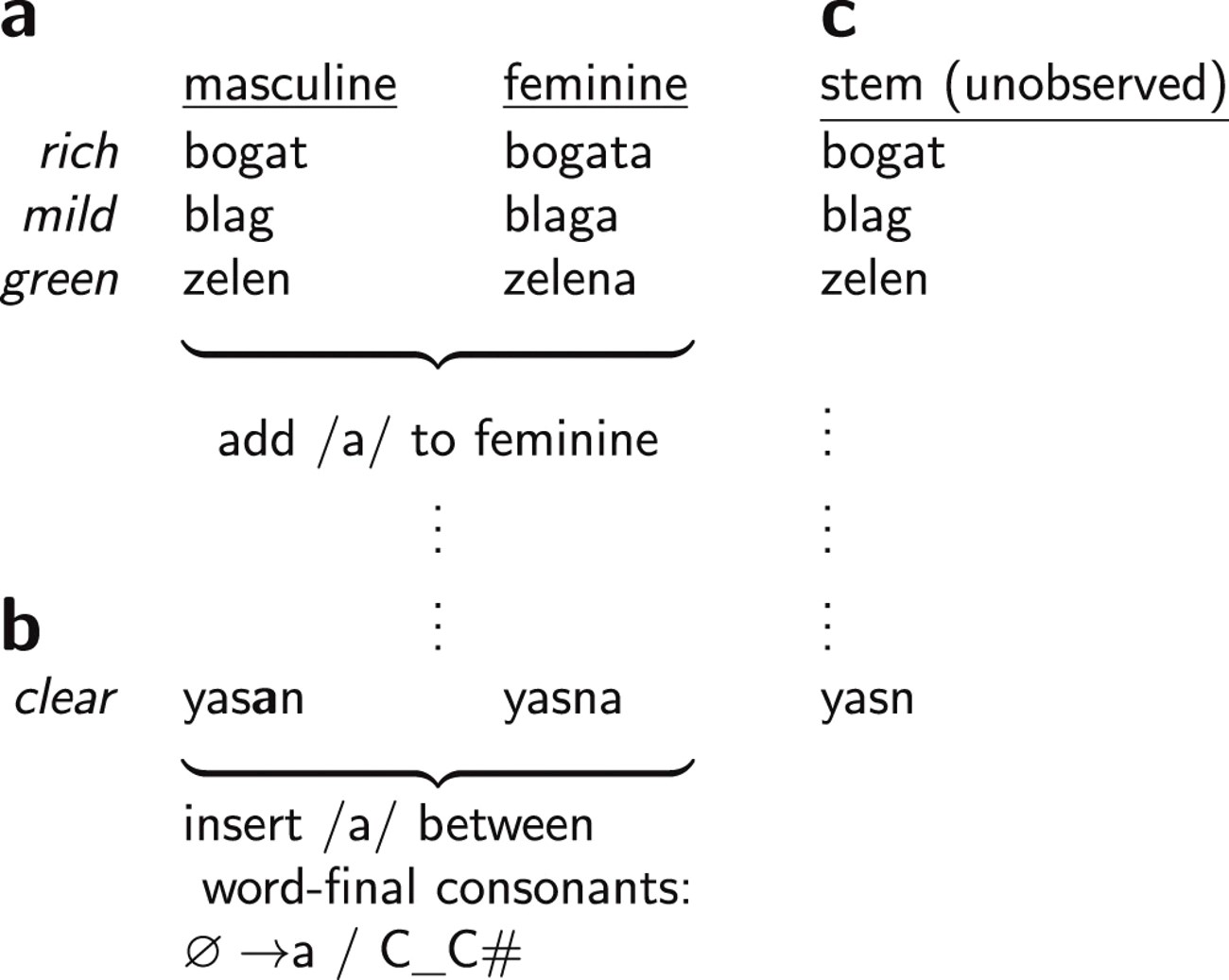
Model može naučiti da se slovo "a" mora dodati na kraj riječi kako bi oblik muškog roda postao ženski


Ljudski jezici su notorno složeni i lingvisti su dugo mislili da bi bilo nemoguće naučiti stroj kako analizirati zvukove govora i strukture riječi na način na koji to rade ljudi. Ali istraživači s MIT-a, Sveučilišta Cornell i Sveučilišta McGill poduzeli su korak u tom smjeru. Oni su demonstrirali sustav umjetne inteligencije koji može sam naučiti pravila i obrasce ljudskih jezika.
Jezični obrasci više razine
Kada se daju riječi i primjeri kako se te riječi mijenjaju da bi izrazile različite gramatičke funkcije - kao što su vrijeme, padež ili rod - u jednom jeziku, ovaj model strojnog učenja dolazi do pravila koja objašnjavaju zašto se oblici tih riječi mijenjaju. Na primjer, može naučiti da se slovo “a” mora dodati na kraj riječi kako bi oblik muškog roda postao ženski u, kako pišu istraživači, "srpskohrvatskom jeziku".
Ovaj model, opisan u časopisu Nature Communications, može automatski naučiti jezične obrasce više razine koji se mogu primijeniti na mnoge jezike, što omogućuje postizanje boljih rezultata.
Suptilne sličnosti
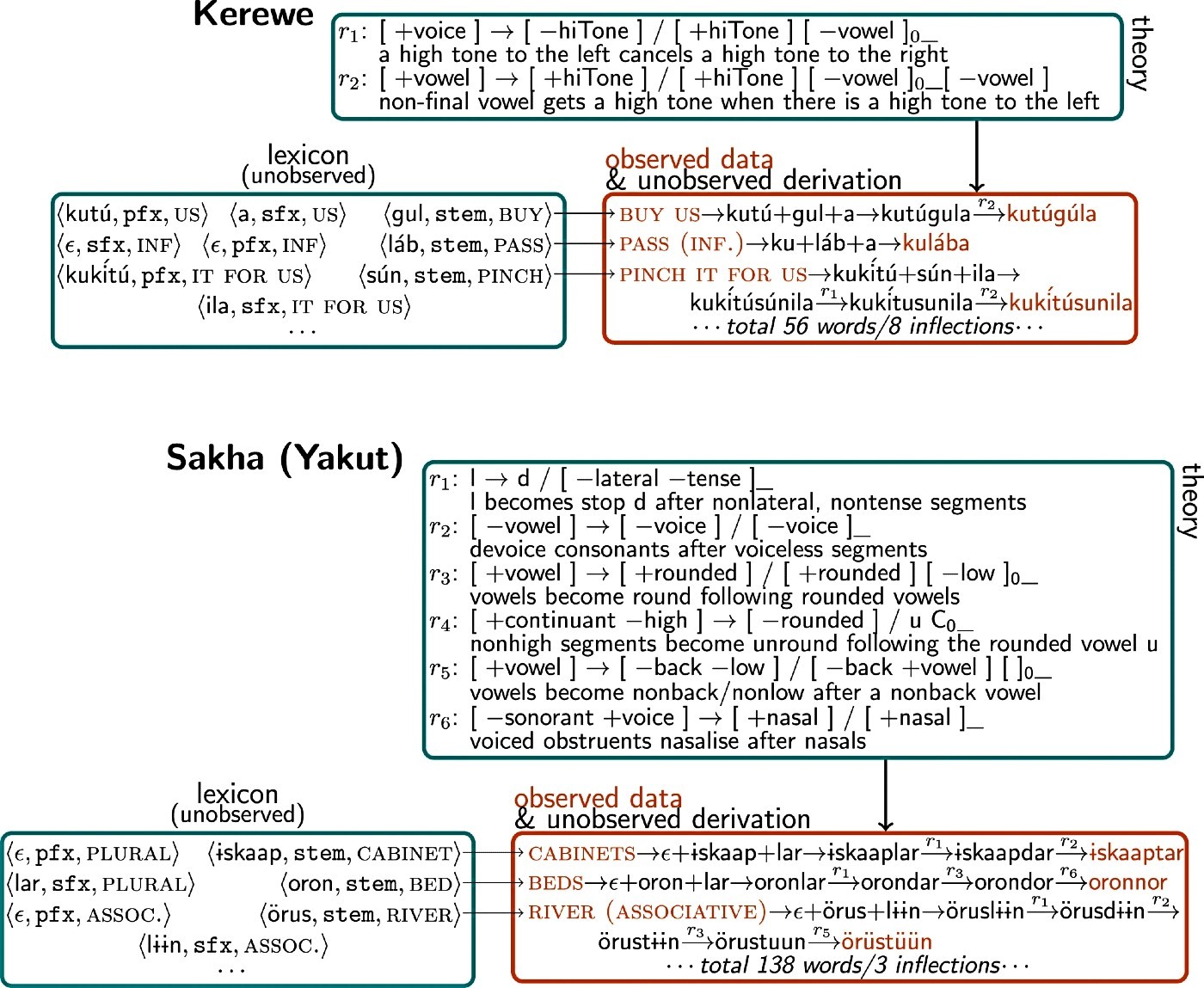
Istraživači su trenirali i testirali model koristeći probleme iz udžbenika lingvistike koji su sadržavali 58 različitih jezika. Svaki je problem imao skup riječi i odgovarajuće promjene oblika riječi. Model je uspio smisliti točan skup pravila za opisivanje tih promjena oblika riječi za 60 posto problema.
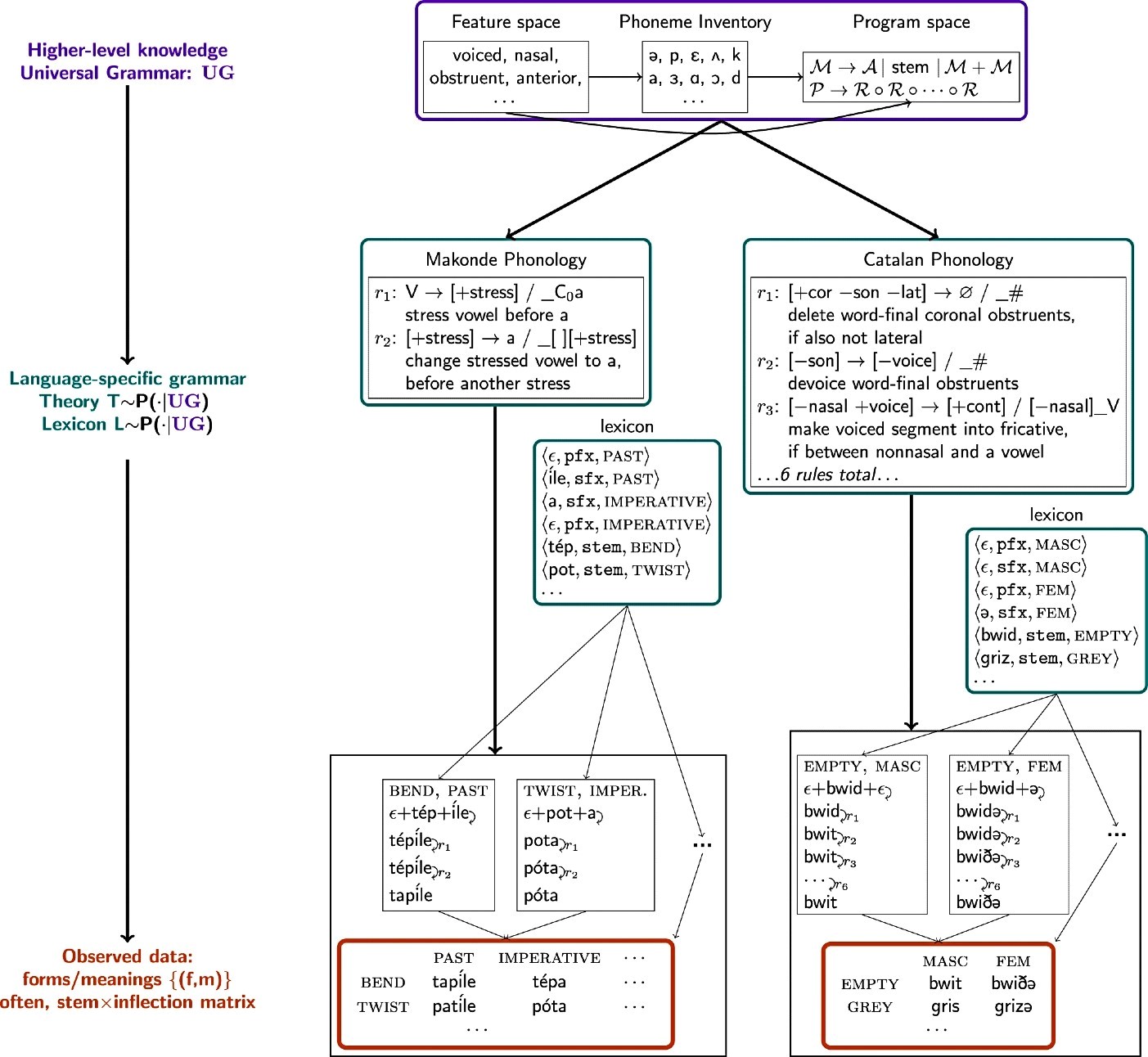
Ovaj bi se sustav mogao koristiti za proučavanje jezičnih hipoteza i istraživanje suptilnih sličnosti u načinu na koji različiti jezici transformiraju riječi. Sustav otkriva modele koje ljudi mogu lako razumjeti, a te modele dobiva iz male količine podataka, iz nekoliko desetaka riječi. Umjesto korištenja masivnog skupa podataka za jedan zadatak, sustav koristi mnogo malih skupova podataka, što je bliže načinu na koji znanstvenici predlažu hipoteze.
Interakcija fonologije i morfologije
U potrazi za UI sustavom koji bi mogao automatski naučiti model iz više povezanih skupova podataka, istraživači su istražili interakciju fonologije i morfologije. Kako bi izgradili model koji bi mogao naučiti gramatiku, koristili tehniku Bayesovog učenja kojom model rješava problem pisanjem računalnog programa.
U budućnosti, istraživači žele koristiti svoj model za pronalaženje neočekivanih rješenja za probleme u drugim domenama. Ovu tehniku mogli bi primijeniti na više situacija u kojima se znanje više razine može primijeniti na međusobno povezane skupove podataka. Na primjer, mogli bi razviti sustav za izvođenje diferencijalnih jednadžbi iz skupova podataka o kretanju različitih objekata.
























