Realistična lica koja govore stvorena od audio zapisa i fotografija
Program temeljen na umjetnoj inteligenciji i strojnom učenju snima zvuk i fotografije iz kojih izrađuje video s realističnim animacijama lica sinkroniziranog s govorom


Na temelju fotografija i zvučnog zapisa glasa neke osobe, istraživači Tehnološkog sveučilišta Nanyang u Singapuru (NTU) razvili su računalni program koji stvara realistične videozapise s izrazima lica i pokretima glave.
Realistične animacije
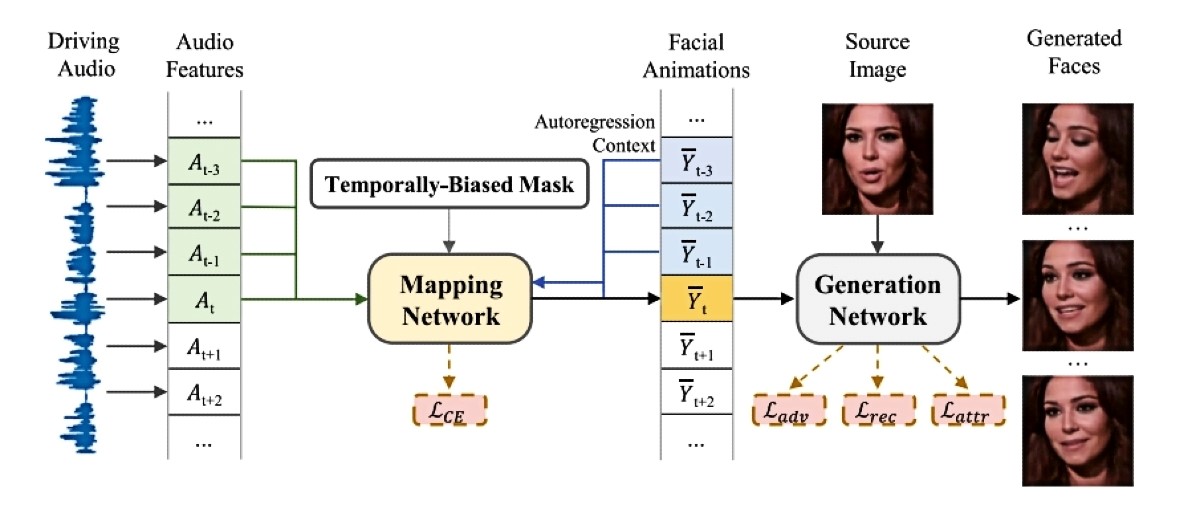
Njihov DIverse yet Realistic Facial Animations, odnosno "raznovrsne, ali realistične animacije lica" ili skraćeno DIRFA je program temeljen na umjetnoj inteligenciji koji snima zvuk i fotografiju i proizvodi 3D video na kojem osobu pokazuje realistične i dosljedne animacije lica sinkronizirane sa zvučnim zapisom.
Stvaranje realističnih izraza lica uz pomoć zvuka složen je izazov. Za određeni audio signal mogu postojati brojni mogući izrazi lica, a te se mogućnosti mogu umnožiti kada se radi o nizu audio signala tijekom vremena. Budući da zvuk obično ima jake veze s pokretima usana, ali slabije veze s izrazima lica i položajem glave, istraživači su se usredotočili na stvaranje lica koja govore i pritom pokazuju preciznu sinkronizaciju usana, bogate izraze lica i prirodne pokrete glave koji odgovaraju pruženom zvuku.
Mnoštvo varijacija
"Govor pokazuje mnoštvo varijacija. Pojedinci izgovaraju iste riječi različito u različitim kontekstima, uključujući varijacije u trajanju, amplitudi, tonu i još mnogo toga. Nadalje, izvan svoje jezične sadržaja, govor prenosi bogate informacije o govornikovom emocionalnom stanju i faktorima identiteta kao što su spol, dob, etnička pripadnost, pa čak i osobine ličnosti", objasnili su istraživači u radu predstavljenom u časopisu Pattern Recognition.

Kako bi predvidjeli znakove iz govora i povezali ih s izrazima lica i pokretima glave, DIRFA-u su obučavali na više od milijun audiovizualnih isječaka oko 6000 ljudi iz baze podataka otvorenog koda The VoxCeleb2 Dataset.
Transformacija ulaza
DIRFA je modelirala vjerojatnost animacije lica, poput podignute obrve ili naboranog nosa, na temelju ulaznog zvuka. Ovo modeliranje je omogućilo programu da transformira audio ulaz u različite, ali vrlo realistične sekvence lica animacije koje će voditi generaciju lica koja govore.
Istraživači vjeruju da bi DIRFA mogla omogućiti nove načine primjene u raznim industrijama i područjima, uključujući zdravstvo, jer bi mogla omogućiti sofisticiranije i realističnije virtualne asistente i chatbotove i poboljšati korisnička iskustva. DIRFA bi, kažu oni, mogla postati moćan alat za osobe s poteškoćama u govoru ili pomicanju lica i pomoći im da svoje misli i emocije prenesu putem ekspresivnih avatara ili digitalnih prikaza.

Opsežni eksperimenti pokazali su da DIRFA može generirati lica koja govore s točnim pokretima usana, živopisnim izrazima lica i prirodnim položajem glave. Singapurski stručnjaci na tome ne staju i sad rade na poboljšanju sučelja programa, dodatnim opcijama i finom podešavaju izraza lica.