Najveća biblioteka realističnih dizajna automobila
MIT-ov skup open-source podataka obuhvaća više od 8000 različitih dizajna i trebala bi ubrzati oblikovanje novih, aerodinamičnih modela


Inženjeri MIT-a razvili su najveći skup open-source podataka dizajna automobila, uključujući njihovu aerodinamiku. Korištenje ove baze podataka moglo bi, kažu, znatno ubrzati dizajn ekološki prihvatljivih automobila i električnih vozila. Alati generativne umjetne inteligencije koji mogu pretražiti ogromne količine podataka u sekundi i pronaći veze za generiranje novog dizajna dakako već postoje, no podaci iz kojih bi trebali učiti dosad nisu bili dostupni, barem ne u nekom centraliziranom obliku.
3D dizajni
No, MIT-ov DrivAerNet++ čini baš to: ovaj skup podataka obuhvaća više od 8000 dizajna automobila koje su inženjeri generirali na temelju najčešćih tipova automobila. Svaki dizajn predstavljen je u 3D obliku i uključuje informacije o aerodinamici automobila, načinu na koji bi zrak strujao oko danog dizajna na temelju simulacija dinamike fluida koje je grupa provela za svaki dizajn.

Svaki dizajn dostupan je u nekoliko prikaza, poput mreže, oblaka točaka ili jednostavnog popisa parametara i dimenzija dizajna. Kao takav, skup podataka mogu koristiti različiti modeli umjetne inteligencije koji su podešeni za obradu podataka u određenom modalitetu.
Brzi trening
DrivAerNet++ zamišljen je kao opsežna biblioteka realističnih dizajna automobila, s detaljnim podacima o aerodinamici koji se mogu koristiti za brzo treniranje bilo kojeg AI modela. Ovi modeli zatim mogu jednako brzo generirati nove dizajne koji bi mogli dovesti do automobila s većom potrošnjom goriva i električnih vozila s većim dometom, u djeliću vremena koje je potrebno današnjoj automobilskoj industriji.
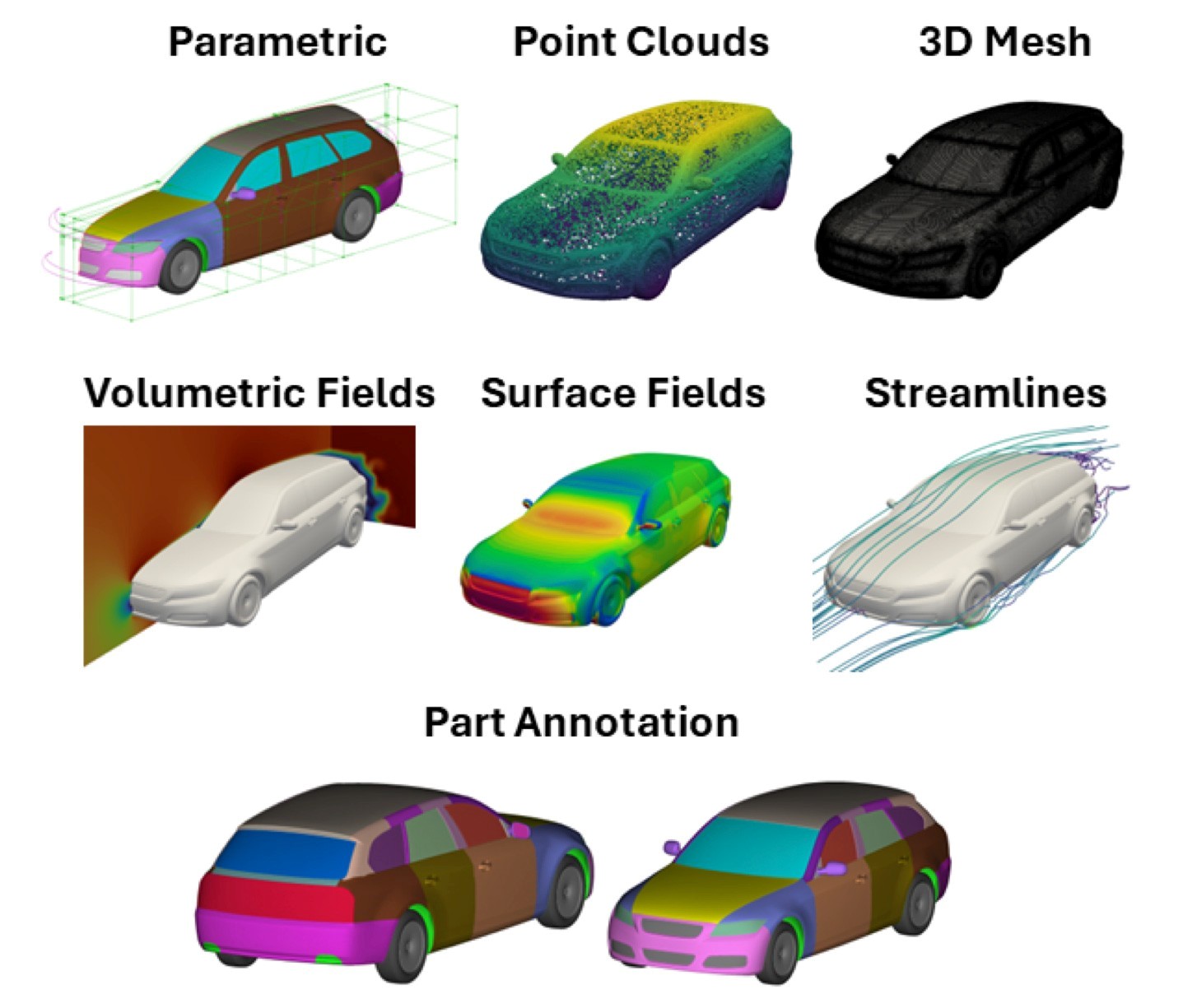
Kako bi izgradili skup podataka o dizajnu automobila s fizički točnim prikazima njihove aerodinamike, istraživači su započeli s nekoliko osnovnih 3D modela tipičnih limuzina, kupea i karavana koje su osigurali Audi i BMW. Na svakom dizajnu potom je izmijenjeno 26 parametara poput duljine, karakteristika podvozja, nagiba vjetrobranskog stakla ili gaznog sloja kotača.
39 terabajta podataka
Algoritam optimizacije osigurao je da svaki novi dizajn bude doista različit, a ne kopija već generiranog dizajna. Svaki 3D dizajn potom je izveden u različite modalitete, tako da se može predstaviti kao mreža, oblak točaka ili popis dimenzija i specifikacija, a složenim računalnim simulacijama dinamike fluida izračunato je kako će zrak strujati oko svakog generiranog dizajna automobila. Tako je nastalo više od 8000 različitih, fizički preciznih 3D oblika automobila.

Za izradu ovog sveobuhvatnog skupa podataka istraživači su potrošili više od 3 milijuna CPU sati koristeći MIT SuperCloud i pritom generirali 39 terabajta podataka. Za usporedbu, procjenjuje se da bi cjelokupna tiskana kolekcija Kongresne knjižnice iznosila oko 10 terabajta podataka. Pojedinosti o metodama umjetne inteligencije koje bi se mogle primijeniti na ovaj skup podataka bit će predstavljene na konferenciji NeurIPS koja se sredinom prosinca održava u Vancouveru.























