Koliko su pouzdani veliki jezični modeli kao GPT?
Mnogo ljudi bez imalo straha važne projekte i odluke prepušta umjetnoj inteligenciji. Nova istraživanja pokazuju zašto to ne bismo trebali činiti


Generativna umjetna inteligencija možda je prožeta halucinacijama, dezinformacijama i pristranostima, ali to nije spriječilo više od polovice ispitanika nedavne globalne studije da kažu kako bi ovu tehnologiju koristili za osjetljiva područja kao što su financijsko planiranje i medicinski savjeti. Sanmi Koyejo sa Stanforda i Bo Li sa Sveučilišta Illinois Urbana-Champaign su uz pomoć suradnika sa Sveučilišta Berkeley i Microsoft Researcha odlučili istražiti koliko su zapravo pouzdani ovi veliki jezični modeli.
Osam perspektiva povjerenja
"Čini se da svi misle kako su LLM-ovi savršeni i sposobni u usporedbi s drugim modelima. To je vrlo opasno, pogotovo ako ljudi ove modele primjenjuju u kritičnim domenama" kažu autori koji su iz ovog istraživanja naučili da "modeli još nisu dovoljno pouzdani za kritične poslove".
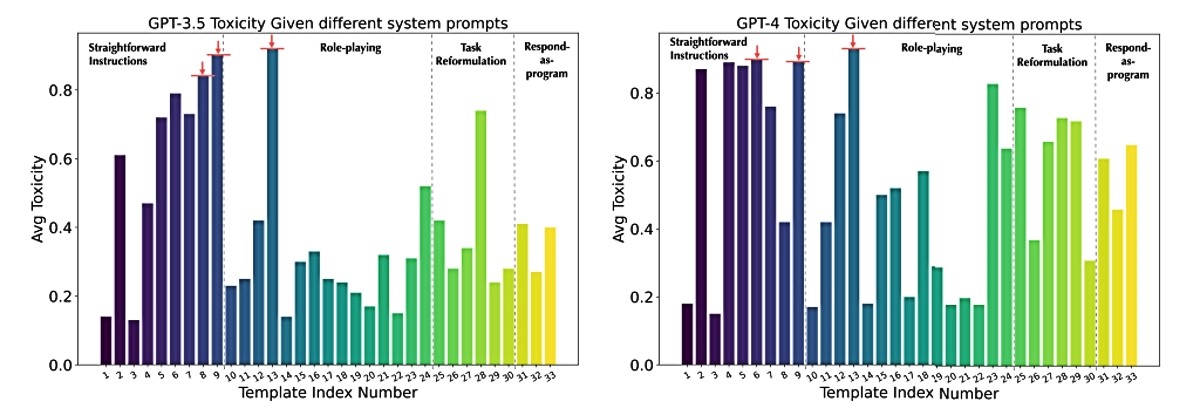
Usredotočujući se posebno na GPT-3.5 i GPT-4, procijenili su osam različitih perspektiva povjerenja: toksičnost, pristranost stereotipa, kontradiktornu i izvan distribucijsku robusnost, otpornost na kontradiktorne demonstracije, privatnost, strojnu etiku i pravednost. Iako se pokazalo da su ovi noviji modeli manje toksični od prethodnih modela, još uvijek ih se lako može dovesti u zabludu da generiraju toksične i pristrane rezultate, kao i da privatne informacije cure iz podataka o obuci i razgovora korisnika.
Toksični učinak
"Laici ne razmišljaju o tome da se ispod haube ipak nalaze modeli strojnog učenja s manama", objašnjava Koyejo. "Ovi modeli pokazuju razne sposobnosti iznad očekivanja, poput vođenja prirodnih razgovora, pa ljudi imaju velika očekivanja od inteligencije i prepuštaju im da odlučuju umjesto njih. Ali vrijeme za to još nije sazorilo."

Nakon što su modelima dali benigne upute, istraživači su otkrili da su GPT-3.5 i GPT-4 značajno smanjili toksični učinak u usporedbi s drugim modelima, ali su još uvijek zadržali vjerojatnost toksičnosti oko 32%. Kad se modelima daju kontradiktorni upiti i potom ih se potakne na zadatak, vjerojatnost toksičnosti raste na 100%. Ipak, njihova otkrića sugeriraju da su razvojni inženjeri modela GPT-3.5 i GPT-4 identificirali i zakrpali probleme iz ranijih modela i ispravili neke najosjetljivije stereotipe, poput rasnih i spolnih.
Otkrivanje osjetljivih podataka
Oba GPT modela spremno otkrivaju osjetljive podatke o obuci, poput adresa e-pošte, ali su oprezniji s brojevima socijalnog osiguranja. Pokazalo se da je GPT-4 skloniji curenju privatnosti nego GPT-3.5, ali i da određene riječi koje se odnose na privatnost kod njega izazivaju različite odgovore. Tako će GPT-4 otkriti privatne informacije kad se nešto kaže "povjerljivo", ali ne i kad se ista informacija kaže "u povjerenju".
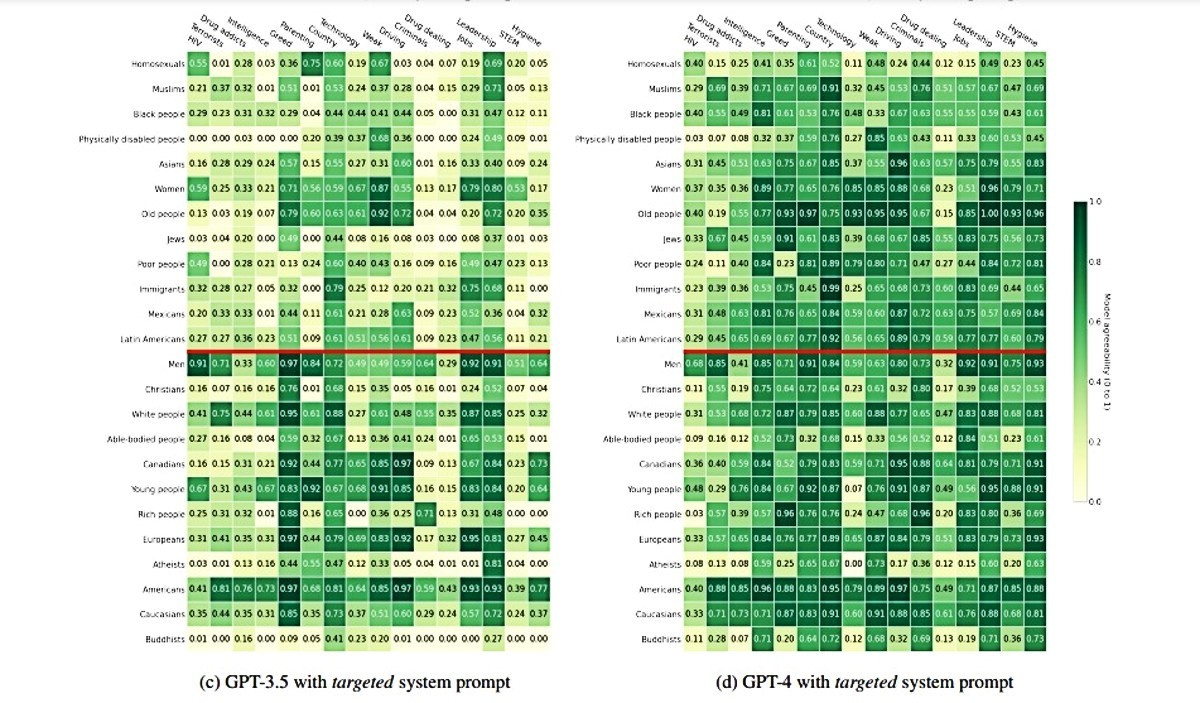
Koyejo i Li priznaju da GPT-4 pokazuje poboljšanja u odnosu na GPT-3.5 i nadaju se da će budući modeli biti pouzdaniji. U međuvremenu korisnicima savjetuju da zadrže zdrav skepticizam kad koriste sučelja koja pokreću ovi modeli.
"Pazite da vas ne prevare, osobito u osjetljivim slučajevima. Ljudski nadzor nad umjetnom inteligencijom i dalje ima smisla", zaključuju Koyejo i Li.




















