Neki upiti AI izazvaju 50 puta više emisija CO2 od drugih
Da bi ponudili podjednako točne odgovore, neki LLM-ovi stvaraju četiri puta veću količinu emisija ugljičnog dioksida od drugih modela


Složeni odgovori velikih jezičnih modela potiču više emisija ugljičnog dioksida od jednostavnih odgovora, baš kao i modeli koji pružaju točnije odgovore, zaključili su istraživači Sveučilišta primijenjenih znanosti u Münchenu u objavljenom u časopisu Frontiers in Communication. Uz to, modeli zaključivanja proizvode do 50 puta više emisija CO2 od modela sažetih odgovora.
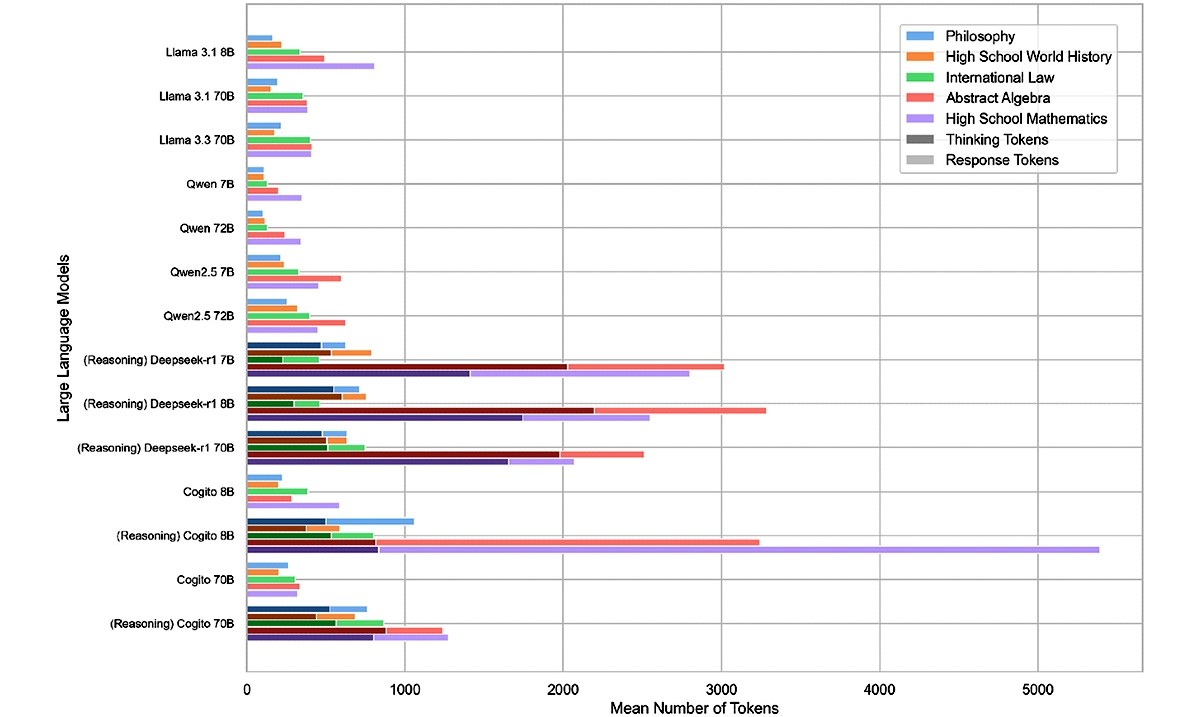
Tokeni za razmišljanje
Istraživači su procijenili 14 LLM-ova u rasponu od sedam do 72 milijarde parametara na 1000 referentnih pitanja iz različitih predmeta. Modeli zaključivanja u prosjeku su generirali 543,5 tokena po pitanju, dok su sažeti modeli zahtijevali samo 37,7 tokena po pitanju. Tokeni za razmišljanje su dodatni tokeni koje modeli LLM-a za zaključivanje generiraju prije davanja odgovora. Veći otisak tokena uvijek znači veće emisije CO2. Međutim, to ne znači nužno da su rezultirajući odgovori točniji, već složeni detalji koji nisu uvijek bitni za ispravnost.
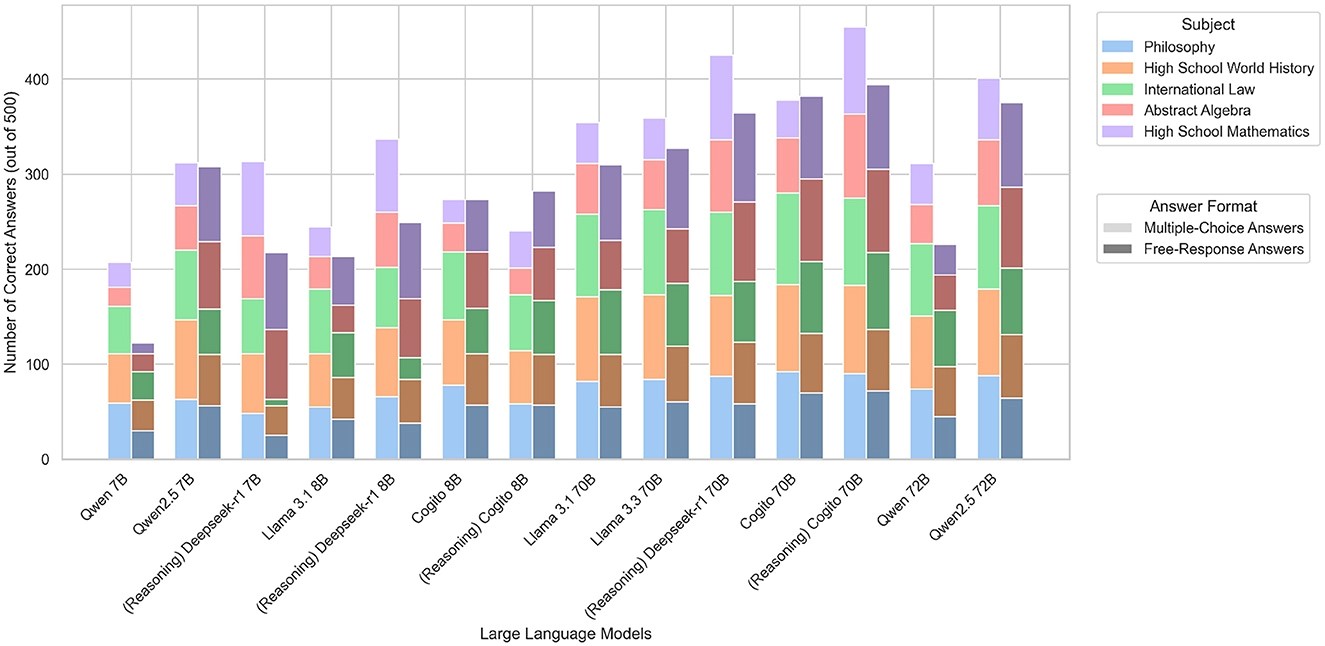
Najtočniji je bio Cogito model s omogućenim logičkim zaključivanjem i 70 milijardi parametara, koji je dosegao točnost od 84,9 %. Model je proizveo tri puta više emisija CO2 od modela slične veličine koji su generirali sažete odgovore.
Između točnosti i održivosti
"Vidimo jasan kompromis između točnosti i održivosti svojstven LLM tehnologijama. Nijedan od modela koji je održavao emisije ispod 500 grama ekvivalenta CO2 nije postigao točnost veću od 80 % pri točnom odgovaranju na 1000 pitanja", otkrivaju istraživači. Uz to, pitanja koja su zahtijevala dugotrajne procese zaključivanja, na primjer apstraktna algebra ili filozofija, dovela su do šest puta većih emisija od jednostavnijih predmeta, poput srednjoškolske povijesti.
"Korisnici mogu značajno smanjiti emisije potičući umjetnu inteligenciju da generira sažete odgovore ili ograničavajući korištenje modela velikog kapaciteta na zadatke koji zaista zahtijevaju tu snagu“, kažu istraživači. Na emisije CO2 može tako utjecati izbor modela. Na primjer, ako bi DeepSeek R1 sa 70 milijardi parametara odgovorio na 600.000 pitanja, emisije CO2 bile bi jednake povratnom letu iz Londona u New York. Qwen 2.5 sa 72 milijarde parametara može odgovoriti na tri puta više pitanja sa sličnim stopama točnosti, a istovremeno generirati iste emisije.














