CALDERA, mali LLM za pohranu na mobitelu
Ovo nije prvi algoritam koji komprimira LLM-ove; novost je inovativna kombinacija dvaju svojstava, "niske preciznosti" i "niskog rangiranja"


Veliki jezični modeli automatiziraju zadatke poput prevođenja, klasifikacije teksta i korisničke službe. No korištenje moći LLM-ova obično zahtijeva slanje zahtjeva centraliziranom poslužitelju, što je skup, energetski intenzivan i često spor proces. No, sada su istraživači Princetona i Stanford Engineeringa osmislili tehniku sažimanja podataka LLM-a koja bi mogla povećati privatnost, uštedjeti energiju i smanjiti troškove. Novi algoritam CALDERA (Calibration Aware Low Precision DEcomposition with Low Rank Adaptation) smanjuje suvišnosti i smanjuje preciznost slojeva informacija. Ova vrsta manjeg LLM-a mogla bi se pohraniti i omogućiti pristup na pametnim telefonima ili prijenosnim računalima i pritom pružiti performanse gotovo jednake nekomprimiranim verzijama.
Mogućnosti kompresije
Istraživači su mogućnosti kompresije isprobali na velikim zbirkama informacija koje se koriste za obuku LLM-a i drugih složenih AI modela, poput onih koji se koriste za klasifikaciju slika. Ovu tehniku, preteču novog pristupa kompresiji LLM-a, isti su istraživači predstavili prošle godine. Skupovi podataka za obuku i AI modeli sastavljeni su od matrica ili mreža brojeva koje se koriste za pohranu podataka, a u slučaju LLM-a riječ je o numeričkim prikazima uzoraka riječi naučenih iz velikih dijelova teksta.
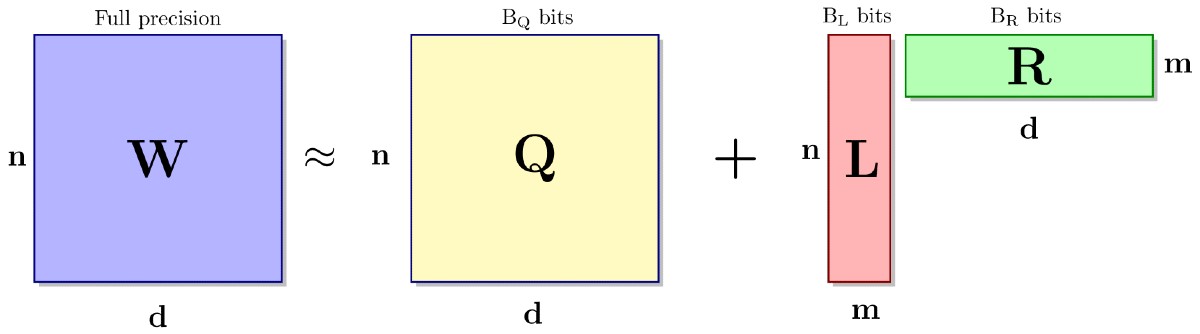
Ovo nije prvi algoritam koji komprimira LLM-ove; novost je inovativna kombinacija dvaju svojstava, "niske preciznosti" (low-precision) i "niskog rangiranja" (low-rank). Budući da digitalna računala pohranjuju i obrađuju informacije kao bitove, prikaz "niske preciznosti" smanjuje broj bitova, ubrzavajući pohranu i obradu uz poboljšanje energetske učinkovitosti. S druge strane, "niski rang" odnosi se na smanjenje redundancija u LLM matricama težine.
Fino podešavanje
"Koristeći oba ova svojstva zajedno, možemo dobiti mnogo veću kompresiju nego što bilo koja od ovih tehnika može postići pojedinačno", objašnjavaju istraživači koji će svoj rad predstaviti na nadolazećoj konferenciji o sustavima obrade neuronskih informacija NeurIPS.Testiranja uz pomoć velikih jezičnih modela otvorenog koda Llama 2 i Llama 3 pokazala su poboljšanja do 5 %, što je značajno za metrike koje mjere nesigurnost u predviđanju nizova riječi.
Korištenje LLM-a komprimiranog na ovaj način moglo bi, kažu, biti prikladno za situacije koje ne zahtijevaju najveću moguću preciznost. Štoviše, mogućnost finog podešavanja komprimiranih LLM-ova na rubnim uređajima poput pametnog telefona ili prijenosnog računala poboljšava privatnost dopuštajući prilagodbu modela bez dijeljenja osjetljivih podataka.























