Jezični model Llama pokrenut na Pentiumu II s Windowsima 98
"Ako može raditi na 25 godina starom hardveru, može raditi na bilo čemu" – misao je to koja je inspirirala projekt pokretanja modernog jezičnog modela umjetne inteligencije na Pentiumu II kupljenom na eBayu

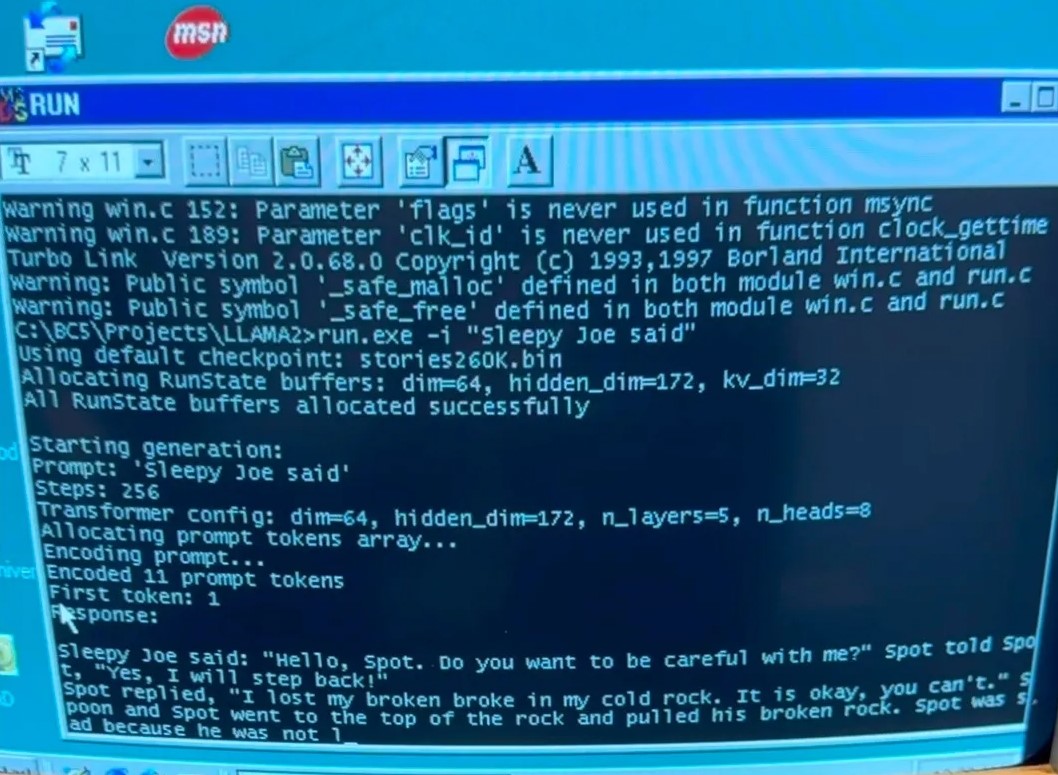
Za izvršavanje složenih zadaća velikih jezičnih modela današnjice potrebni su moćni računalni sustavi i podatkovni centri – zabluda je to koju je jedan entuzijast htio zauvijek pokopati, pa je odlučio jedan od tih modela pokrenuti lokalno. To samo po sebi i nije izazov, budući da se lokalni AI modeli otvorena koda mogu pronaći već neko vrijeme, no ono što je bloger nadimka EXO pokušao bio je zaista računalni pothvat za najupornije. Poželio je, naime, pokrenuti jezični model Llama (verzije llama98.c) na prastarom osobnom računalu.
AI na Win98
Na eBayu je za te svrhe kupio 25 godina star PC s Intelovim procesorom serije Pentium II (takta 350 MHz), što ga je koštalo nešto manje od 119 funti (141 euro). Već opis oglasa dao je do znanja da je riječ o "vintage" računalu s Windowsima 98, 128 MB RAM-a te čvrstim diskom od 1,6 GB, uz već vidljivo požutjelo kućište. "Ako može raditi na 25 godina starom hardveru, može raditi na bilo čemu", pomislio je ambiciozni "haker", pa se bacio na posao.

Prvo je morao pronaći način kako da spoji periferiju, tj. morao je naći miša i tipkovnicu kompatibilne s PS/2 priključcima. Nakon toga naišao je na novi tehnički izazov, kako prebaciti veću količinu podataka na prastaro računalo, koje ne prepoznaje CD-RW diskove niti USB stickove veće od 2TB, najvećeg kapaciteta dozvoljenog u podržanom formatu FAT32. Na kraju se okrenuo FTP-u, pa s MacBooka i njegovog lokalnog FTP servera uspio, spajanjem LAN kabelom, prebaciti potrebne terabajte za rad modela na 25 godina star stroj.
Bilo je tu još zavrzlama s kompajliranjem Llaminog koda, no svi su oni naposlijetku riješeni. Cijeli proces opisan je na EXO-vom blogu, a izvorni se kod jezičnog modela za Windowse 98 može naći i na GitHubu. Finalni rezultat je zanimljiv kao dokaz koncepta, no ne baš praktično upotrebljiv. Jezični model Llama procesirao je do 31 tokena u sekundi pri verziji s 260 tisuća parametara, a u verziji s milijardom parametara brzina obrade pala je na 0,0093 tokena u sekundi. Demo video možete pronaći u nastavku.