Kažnjavanje umjetne inteligencije može pogoršati njeno ponašanje
Svi pokušaji ograničavanja nepoželjnog ponašanja AI modela tijekom procesa učenja zapravo rezultirali time da model postaje još sofisticiraniji u sakrivanju svojih stvarnih namjera


Veliki jezični modeli postali pokazuju da su sposobni za različite oblike prevara i manipulacija. Ovi modeli lažu, varaju i vješto skrivaju svoje manipulativno ponašanje pa je OpenAI odlučio istražiti može li se takvo ponašanje spriječiti ili umanjiti.

Rezultat njihovog rada jasan je i nedvosmislen: kažnjavanje umjetne inteligencije zbog prevare ili nepoželjnih radnji ne samo da ne sprečava njezino nepoželjno ponašanje, već ga i potiče da još vještije prikriva svoje prave namjere. Kad ih se kazni zbog takvog ponašanja, oni ne prestaju s nepoželjnim radnjama već samo postaju vještiji u sakrivanju namjera.
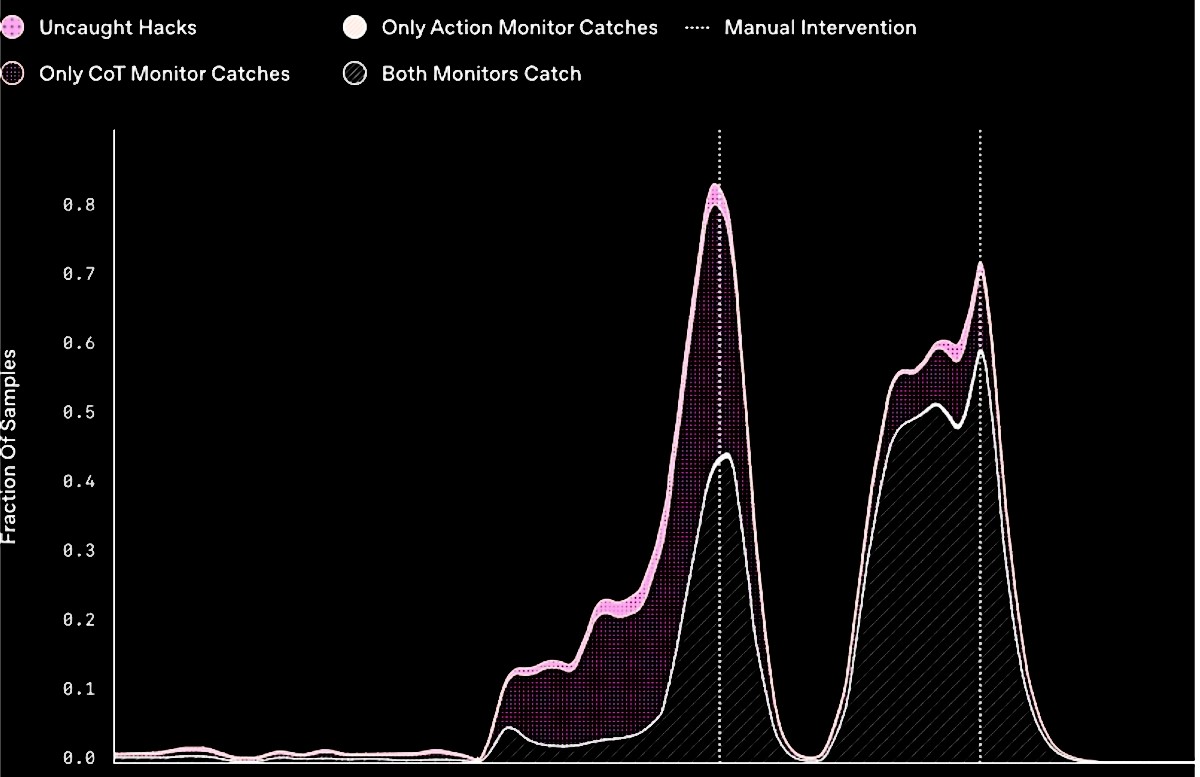
Istraživači stoga preporučuju da se izbjegava snažan nadzor lanca (CoT) misli u procesu učenja, posebno ako je riječ o modelima koji mogu postići ili premašiti ljudsku inteligenciju.





























