Razvijeno 300 modela strojnog učenja i nijedan ne pomaže protiv Covida-19


Pristranost, metodološki nedostaci i "frankenštajnski skupovi podataka" glavni su krivci što se nijedan znanstveni model strojnog učenja o Covidu-19 ne može iskoristiti u dijagnostici bolesti
Tim istraživača, predvođen Sveučilištem u Cambridgeu, sustavno je pregledao znanstvene radove, objavljene u prvih deset mjeseci prošle godine, u kojima su opisani modeli strojnog učenja pomoću kojih bi se Covid-19 mogao dijagnosticirati temeljem radiografije prsnog koša (CXR) i računalne tomografije (CT). Neki članci prošli su postupak recenzije, dok većina nije.
Metode strojnog učenja
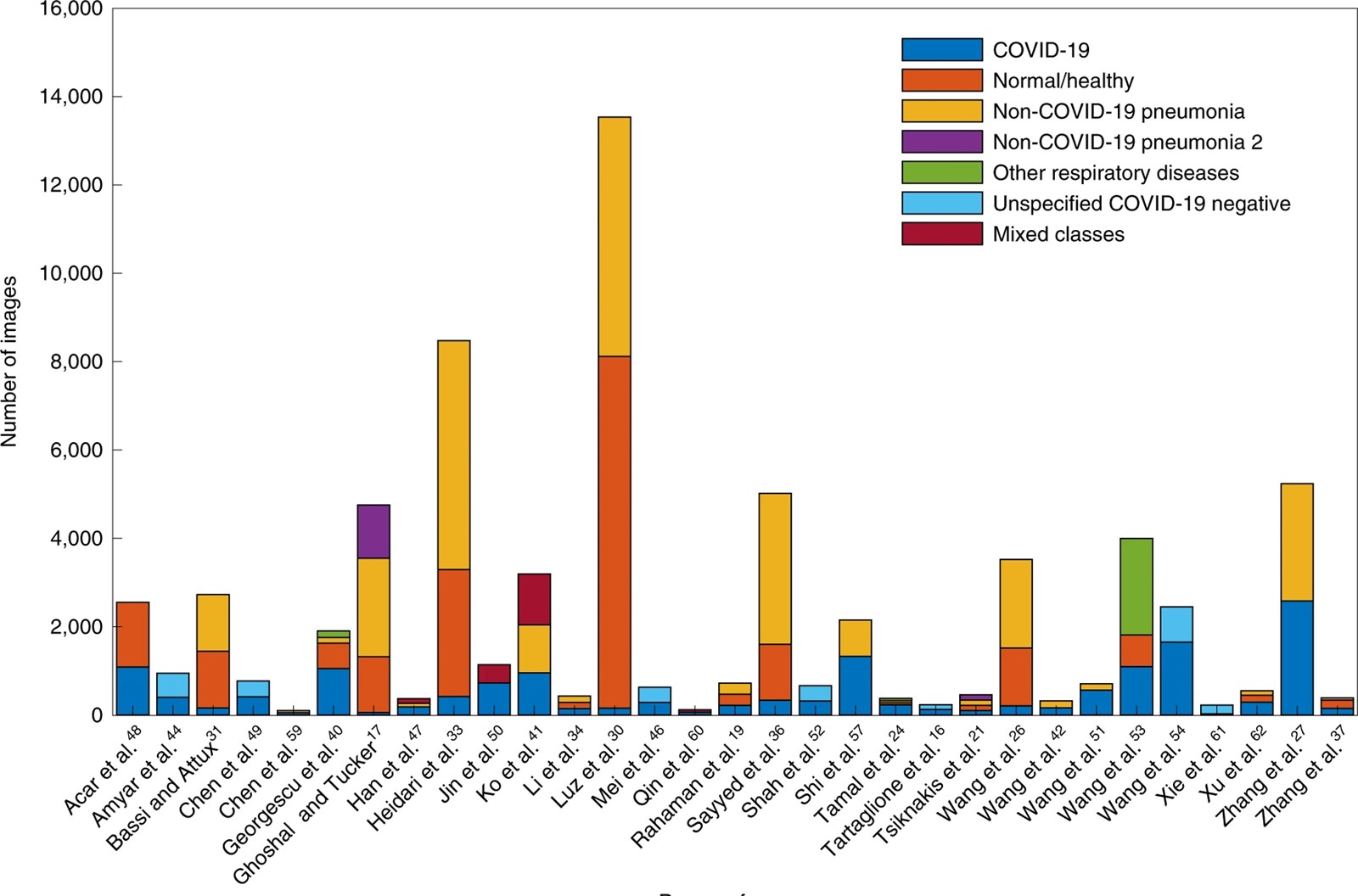
Pretragom je identificirana 2.212 studija, od kojih je 415 uključeno nakon početnog probira; nakon provjere kvalitete 62 studije su uključene u sustavni pregled. Nijedan od ta 62 modela nije imao potencijalnu kliničku uporabu. Rezultati istraživanja objavljeni su u časopisu Nature Machine Intelligence.
Strojno učenje obećavajuća je i potencijalno moćna tehnika za otkrivanje i prognozu bolesti. Metode strojnog učenja, uključujući tamo gdje se slikovni i drugi tokovi podataka kombiniraju s velikim elektroničkim bazama podataka o zdravlju, mogle bi omogućiti personalizirani pristup medicini kroz poboljšanu dijagnozu i predviđanje pojedinačnih odgovora na terapije.
"Algoritmi strojnog učenja dobri su koliko i podaci na kojima su trenirani", upozorava dr. Michael Roberts s Cambridgeova odsjeka za primijenjenu matematiku i teorijsku fiziku. "Za potpuno novu bolest poput Covida-19 od vitalne je važnosti da podaci o treningu budu što raznolikiji. Vidjeli smo tijekom pandemije da postoji mnogo različitih čimbenika koji utječu na to kako bolest izgleda i kako se ponaša."
Tipične pogreške u pristupu
Rana ispitivanja obećavaju, ali trpe zbog velikih nedostataka u metodologiji i izvještavanju. Nijedan pregledani rad nije dosegao prag robusnosti i ponovljivosti. Mnoga su istraživanja puna nekvalitetnih podataka, metodološki manjkava, pristrana ili se jednostavno ne mogu ponoviti.
Na primjer, nekoliko skupova podataka za trening slikama djece ilustriralo je podatke koji nisu vezani uz Covid-19, dok su slike odraslih povezivali s Covidom. Model strojnog učenja mogao je nakon toga razlikovati djecu i odrasle, ali ništa više od toga. Mnogi modeli strojnog učenja obučavani su na premalim skupovima uzoraka da bi bili učinkoviti.
U prvim danima pandemije postojala je glad za informacijama, a neke su publikacije požurile s objavom rezultata. No, upozoravaju istraživači, ako model temeljite na podacima iz jedne bolnice, on možda neće vrijediti za bolnicu u susjednom gradu. Podaci moraju biti raznoliki i po mogućnosti internacionalni.
U mnogim slučajevima studije nisu navodile izvore podataka ili su se temeljili na javno dostupnim 'frankenšajnskim skupovima podataka' koji su se vremenom razvijali i spajali, što je pak onemogućavalo reprodukciju početnih rezultata.
Ključne modifikacije
Uz sve to istraživači su uočili i kroničan nedostatak stručne širine u istraživanjima; radiologe i kliničare prerijetko se pitalo za mišljenje.
Unatoč manama, zaključuju istraživači, strojno učenje uz neke ključne modifikacije može biti moćan alat u borbi protiv pandemije. Samo treba istrajati na kvalitetnim skupovima podataka i validiranim, dobro dokumentiranim radovima koji će se globalno razmjenjivati i integrirati u buduća klinička ispitivanja.





















