Ruska metoda finog podešavanja modela za istraživanje mišljenja
Javno dostupan model na ruskom jeziku učinkovito analizira sentimente u različitim područjima


Ruski znanstvenici razvili su novi pristup modelima obuke za analizu sentimenta internetskih tekstova koji omogućava brzo i jeftino fino podešavanje modela za različite potrebe, od marketinga, preko političkih znanosti do sociološka istraživanja. Rad ruskih znanstvenika objavljen je u časopisu IEEE Access.
Proučavanje utjecaja
Analiza sentimenta je proces identificiranja, mjerenja i tumačenja pozitivnih ili negativnih mišljenja izraženih u velikim količinama tekstualnih podataka na internetu. Ova se metoda istraživanja mišljenja koristi u sustavima preporuka, analizi vijesti, političkim znanostima, marketinškim i sociološkim istraživanjima.
Uz to, takva se analiza može koristiti za proučavanje utjecaja objava na društvenim mrežama na učinkovitost marketinških kampanji, reakcija potrošača na proizvode tvrtke pa i za predviđanje kretanja na burzi na temelju raspoloženja na društvenim mrežama.
Ubrzavanje modela
Tijekom proteklih nekoliko godina postignut je značajan napredak u analizi sentimenata, posebice primjenom dubokih neuronskih mreža u obradi teksta. Međutim, problemi nastaju kad se obučeni model prenese iz jednog područja u drugo. Na primjer, model za analizu recenzija restorana neće dobro funkcionirati s recenzijama banaka.

Znanstvenici danas pokušavaju pronaći način da ubrzaju prijenos modela i učine ga učinkovitijim jer bi to uštedjelo mnogo novca i truda. Drugi izazov s kojim se suočavaju znanstvenici je kako brzo i jeftino poboljšati kvalitetu analize raspoloženja pomoću neuronske mreže u određenoj domeni.
Brz prijenos modela
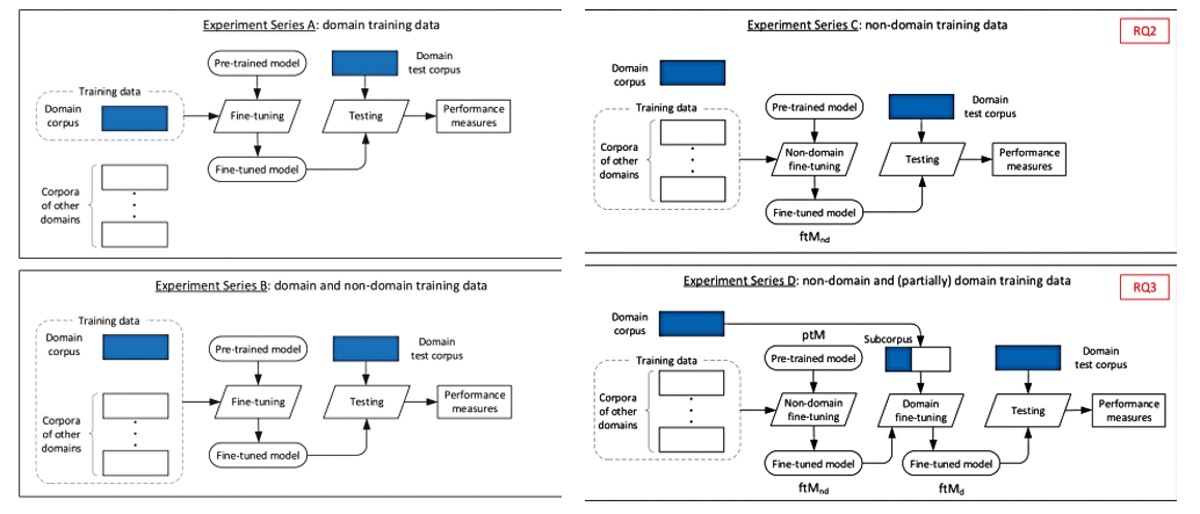
Istraživači Laboratorija za inteligentne sustave Državnog sveučilišta Vjatka razvili su tako pristup koji omogućuje brz prijenos modela analize sentimenta. Autori su otkrili da će kod prijenosa nekog univerzalnog modela analize sentimenta, treniranog na velikoj kolekciji različitih tekstova iz jednog područja, kvaliteta analize biti niska. To znači da model treba fino podesiti.
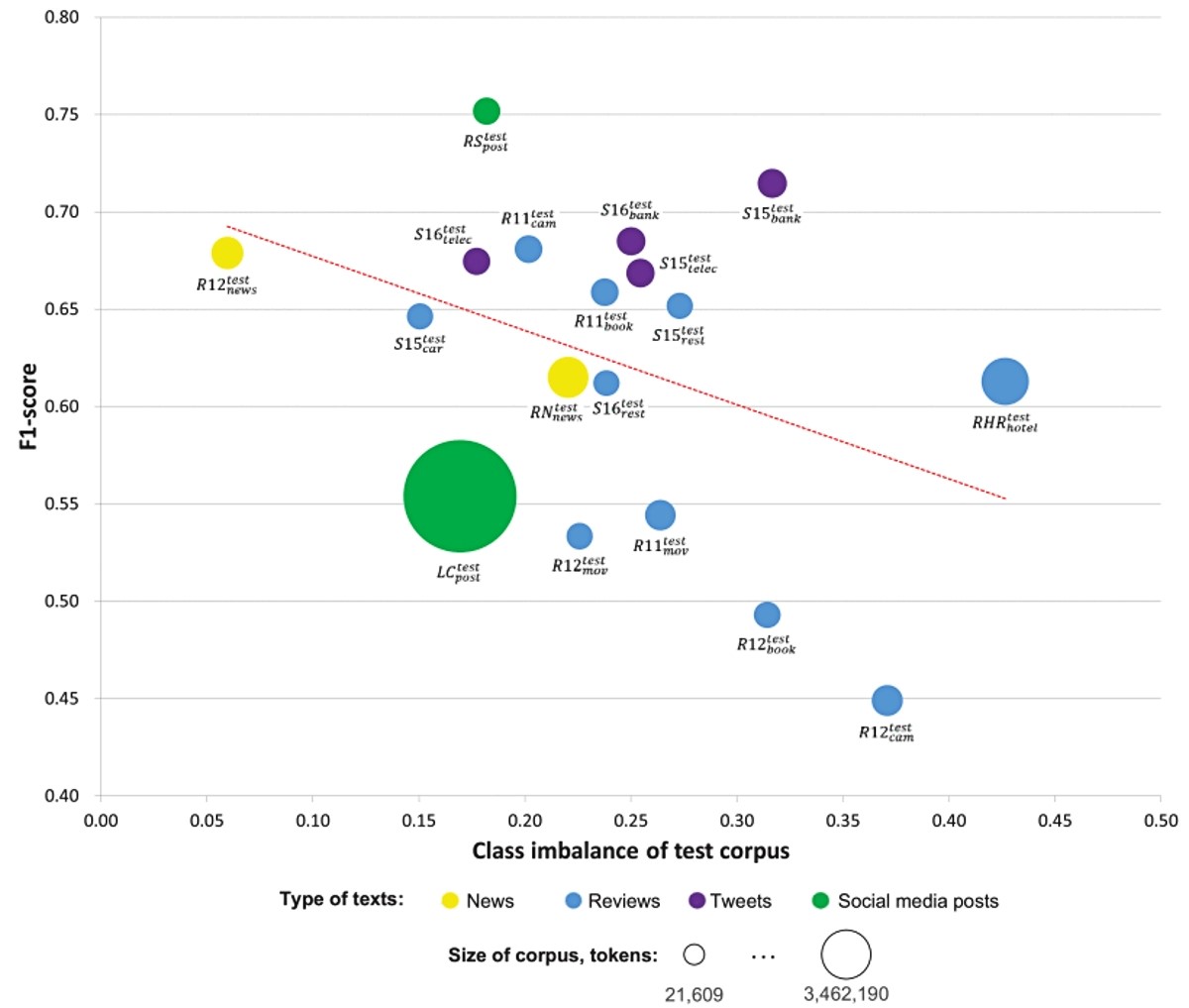
Istraživanje velikih razmjera na više od 280 tisuća tekstova na ruskom jeziku pokazalo je da fino podešavanje univerzalnog modela zahtijeva samo nekoliko stotina označenih tekstova iz novog područja, a ne tisuće ili desetke tisuća kao za primarnu obuku. Uz to, autori su uvježbali međudomenski model na ruskom jeziku koji učinkovito analizira sentimente u različitim područjima i učinili ga javno dostupnim.














