Umjetna inteligencija koja odnose između objekata razumije poput čovjeka
Novi model strojnog učenja, osmišljen na MIT-u, mogao bi omogućiti robotima da razumiju interakcije u svijetu na način na koji to čine ljudi


Kad ljudi gledaju prizor, vide objekte i odnose među njima. Na vrhu vašeg stola može se nalaziti prijenosno računalo koje se nalazi s lijeve strane telefona, a koji je ispred monitora računala. Mnogi modeli dubokog učenja muče se vidjeti svijet na ovaj način jer ne razumiju odnose između pojedinačnih objekata.
Bez znanja o tim odnosima, robot dizajniran da pomogne nekome u kuhinji imao bi poteškoća s praćenjem naredbe poput “podigni lopaticu koja se nalazi lijevo od štednjaka i stavi je na dasku za rezanje”.

Jedna po jedna veza
U nastojanju da riješe ovaj problem, istraživači MIT-a razvili su model koji razumije temeljne odnose između objekata na sceni. Njihov model predstavlja pojedinačne odnose jedan po jedan, a zatim kombinira te prikaze kako bi opisao cjelokupnu scenu. To omogućuje modelu da generira točnije slike iz tekstualnih opisa, čak i kada scena uključuje nekoliko objekata koji su raspoređeni u različitim odnosima jedan s drugim.
Ovaj bi se rad mogao primijeniti u situacijama kad industrijski roboti moraju obavljati zamršene zadatke manipulacije u više koraka, poput slaganja predmeta u skladištu ili sastavljanja uređaja. Također to je korak bliže izradi strojeva koji mogu učiti iz svog okruženja i komunicirati s njim na sličan način kako to čine ljudi.

"Kad pogledam tablicu, ne mogu reći da postoji objekt na lokaciji XYZ. Naši umovi ne rade tako. U našim mislima scenu razumijemo na temelju odnosa između objekata. Mislimo da bismo izradom sustava koji može razumjeti odnose između objekata mogli koristiti taj sustav za učinkovitiju manipulaciju i promjenu našeg okruženja", kaže glavni autor rada Yilun Du, doktorand u Laboratoriju za računalnu znanost i umjetnu inteligenciju (CSAIL).
Istraživanje će biti predstavljeno na virtualnoj Konferenciji o neuronskim sustavima za obradu informacija NeurIPS 2021.
Jedna po jedna veza
Okvir koji su razvili istraživači može generirati sliku scene na temelju tekstualnog opisa objekata i njihovih odnosa poput "drveni stol lijevo od plave stolice. Crveni kauč desno od plave stolice".
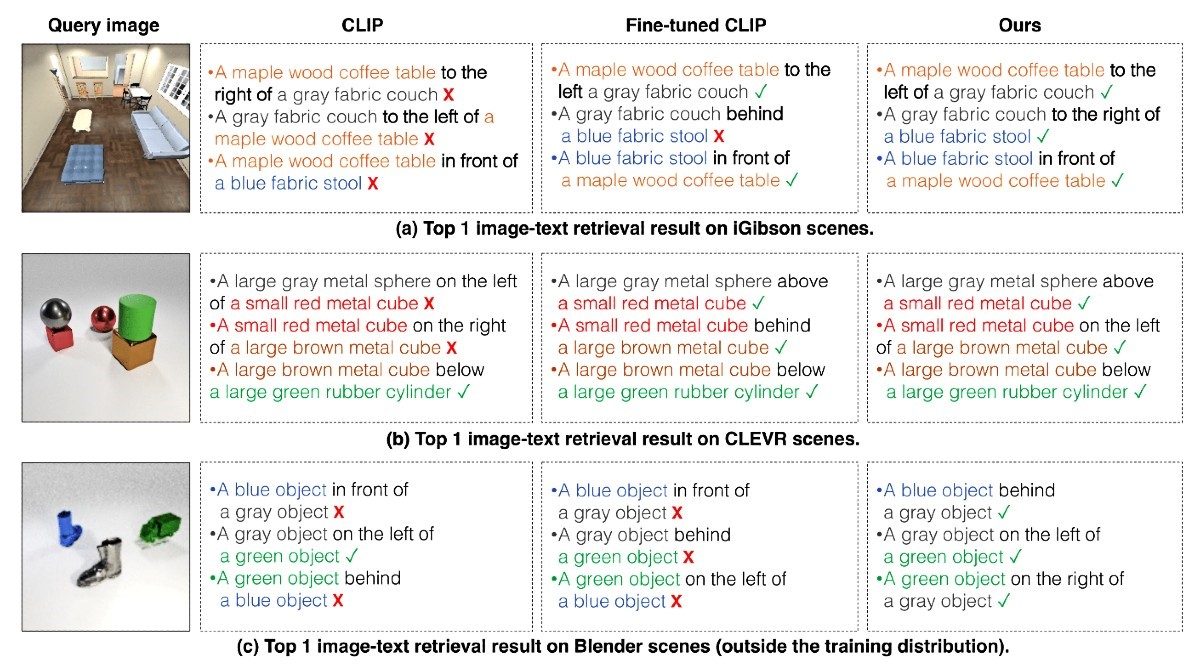
Njihov bi sustav rastavljao ove rečenice na dva manja dijela koji opisuju svaki pojedinačni odnos ("drveni stol lijevo od plave stolice" i "crveni kauč desno od plave stolice"), a zatim modelirao svaki dio zasebno. Ti se dijelovi zatim kombiniraju kroz proces optimizacije koji generira sliku scene.
Rastavljanjem rečenica na kraće dijelove za svaki odnos, sustav ih može rekombinirati na različite načine, tako da se bolje prilagođava opisima scena koje prije nije vidio.
Sustav također radi obrnutim redoslijedom - pomoću slike može pronaći tekstualne opise koji odgovaraju odnosima između objekata u sceni. Uz to, model se može koristiti za uređivanje slike preuređivanjem objekata u sceni tako da odgovaraju novom opisu.
Razumijevanje složenih scena
Istraživači su model usporedili s drugim metodama dubokog učenja koje su dobile tekstualni opis i zadaću generiranja slika koje prikazuju odgovarajuće objekte i njihove odnose. U svakom je slučaju njihov model nadmašio osnovne vrijednosti.
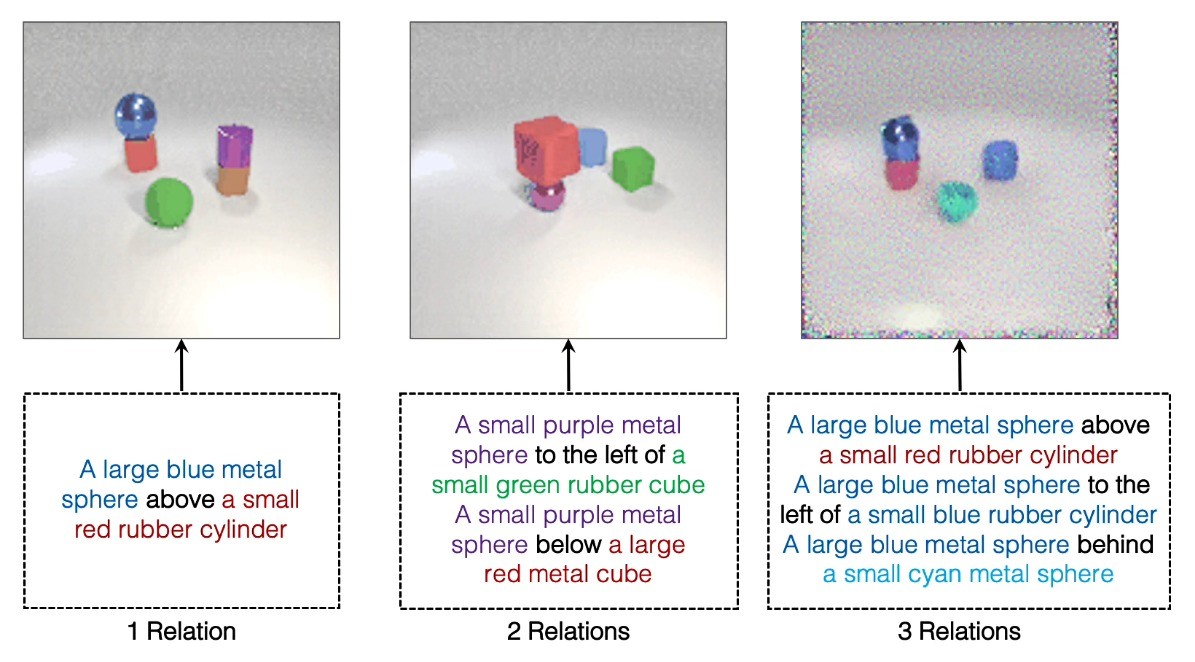
Također su tražili od ljudi da procijene odgovaraju li generirane slike originalnom opisu scene. U najsloženijim primjerima, gdje su opisi sadržavali tri odnosa, 91 posto sudionika zaključilo je da je novi model bolji.

A kada su istraživači sustavu dali dva opisa relacijskih scena koji su opisivali istu sliku, ali na različite načine, model je uspio shvatiti da su opisi ekvivalentni. Istraživači su bili impresionirani robusnošću svog modela, posebno kada je radilo s opisima s kojima se prije nije susreo.
"Ovo je vrlo obećavajuće jer je to bliže načinu na koji ljudi funkcioniraju. Ljudi mogu izvući korisne informacije iz samo nekoliko primjera i kombinirati ih kako bi stvorili beskonačne kombinacije. I naš model ima svojstvo koje mu omogućuje učenje iz manje podataka i generaliziranje na složenije scene", objašnjavaju istraživači.
Ugradnja u robotske sustave
Iako rani rezultati ohrabruju, istraživači žele vidjeti kako njihov model djeluje na složenijim slikama stvarnog svijeta, s bučnim pozadinama i objektima koji blokiraju jedni druge. Zanima ih i ugradnja modela u robotske sustave. To bi robotima omogućilo da zaključe odnose objekata iz videa, a zatim to znanje primijene za manipulaciju objektima u stvarnom svijetu.



























