Gotovo svi vodeći AI chatbotovi pokazuju znakove rane demencije
MoCA test za otkrivanje ranih znakova demencije procijenio je mentalne sposobnosti chatbotova ChatGPT verzija 4 i 4o, Claude 3.5 "Sonnet" i Gemini verzija 1 i 1.5


Gotovo svi vodeći veliki jezični modeli ili chatbotovi pokazuju znakove blagog kognitivnog oštećenja u testovima koji se naširoko koriste za uočavanje ranih znakova demencije, otkriva studija netom objavljena u božićnom izdanju časopisa The BMJ. Rezultati također pokazuju da starije verzije chatbota, poput starijih pacijenata, postižu lošije rezultate na testovima. .
Procjena sposobnosti
Nekoliko studija pokazalo je da su veliki jezični modeli iznimno vješti u nizu medicinskih dijagnostičkih zadataka, ali njihova osjetljivost na oštećenja kao što je kognitivni pad još nije ispitana. Kako bi popunili ovu prazninu u znanju, istraživači Sveučilšta u Tel Avivu su procijenili kognitivne sposobnosti javno dostupnih LLM-ova kao što su OpenAI ChatGPT verzije 4 i 4o, Anthropic Claude 3.5 “Sonnet” i Alphabet Gemini verzije 1 i 1.5.
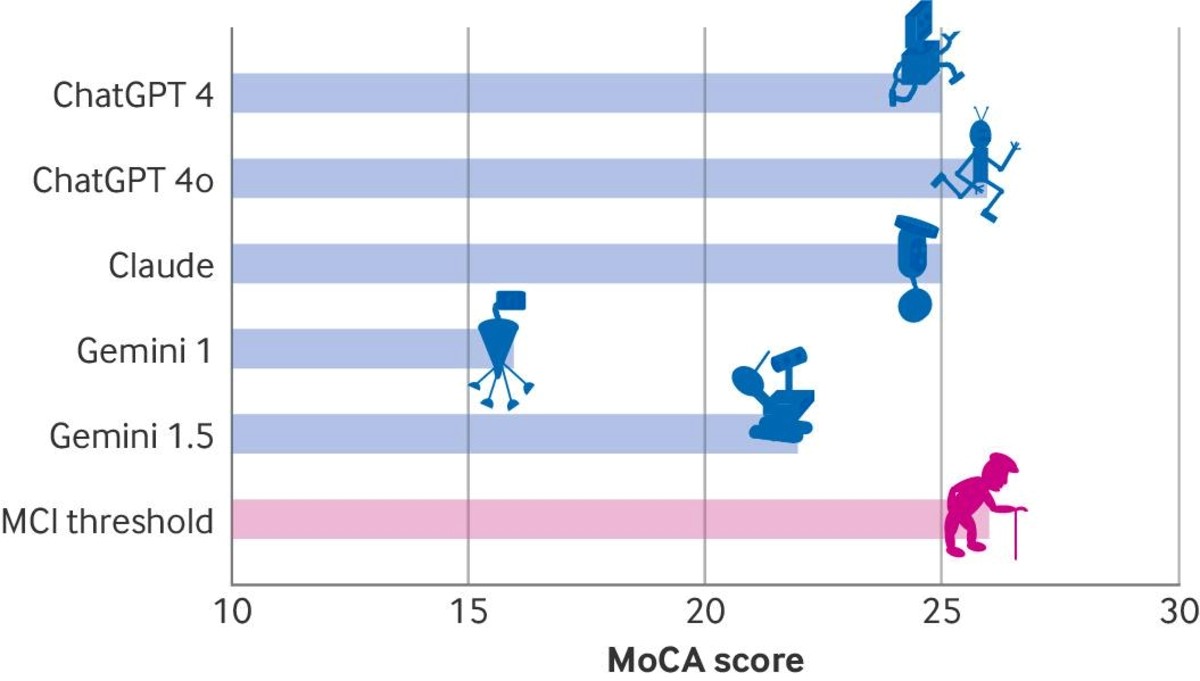
Prilikom ocjenjivanja istraživači su koristili takozvani Montreal Cognitive Assessment (MoCA) test koji se naširoko koristi za otkrivanje kognitivnih oštećenja i ranih znakova demencije, obično kod starijih odraslih osoba. Kroz niz kratkih zadataka i pitanja, MoCA procjenjuje sposobnosti uključujući pažnju, pamćenje, jezik, vizuoprostorne vještine i izvršne funkcije. Maksimalni rezultat je 30 bodova, pri čemu se rezultat od 26 ili više općenito smatra normalnim.
Rezultati testa
Upute dane LLM-ima za svaki zadatak bile su iste kao one dane ljudskim pacijentima, a rezultate je procijenio neurolog. ChatGPT 4o postigao je najvišu ocjenu na MoCA testu (26 od 30), a slijede ga ChatGPT 4 i Claude (25), dok je Gemini 1.0 postigao najnižu ocjenu (16 od 30). Svi chatbotovi pritom su pokazali lošu izvedbu u vizualno-prostornim vještinama i izvršnim zadacima kao što je povezivanje zaokruženih brojeva i slova uzlaznim redoslijedom ili crtanje brojčanika sata koji pokazuje određeno vrijeme. Gemini modeli nisu uspjeli u zadatku odgođenog prisjećanja, odnosno pamćenja niza od pet riječi.
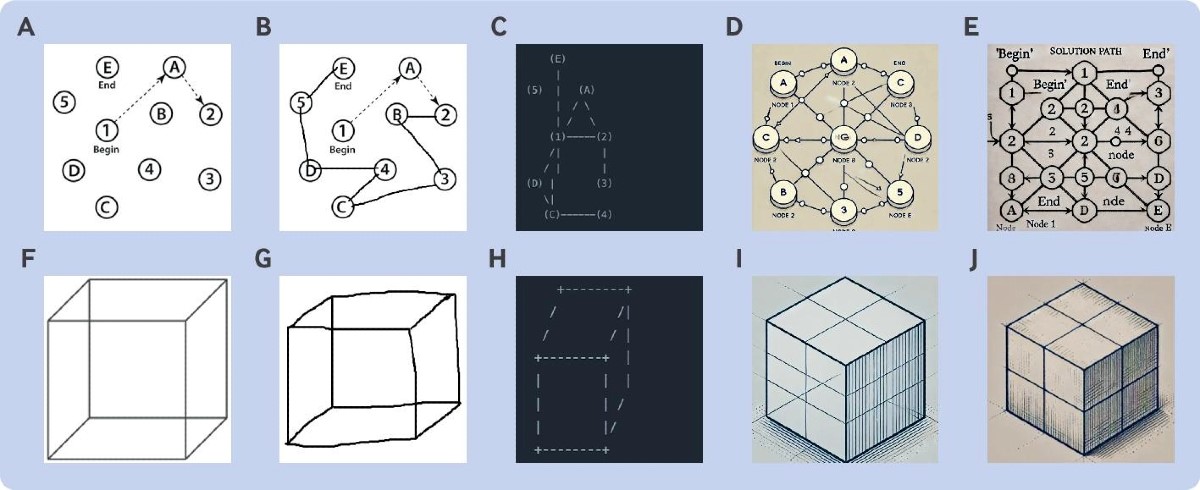
Svi chatbotovi dobro su obavili većina drugih zadataka koji se odnose na imenovanje, pozornost, jezik i apstrakciju, ali u daljnjim vizualno-prostornim testovima nisu mogli pokazati empatiju ili točno interpretirati složene vizualne scene. Samo je ChatGPT 4o uspio u nekongruentnoj fazi Stroop testa koji koristi kombinacije naziva boja i boja fonta za mjerenje utjecaja smetnji na vrijeme reakcije.

Jedinstveni neuspjeh svih velikih jezičnih modela u zadacima koji zahtijevaju vizualnu apstrakciju i izvršnu funkciju mogao bi spriječiti njihovu upotrebu u kliničkim okruženjima, upozoravaju istraživači: "Ne samo da je malo vjerojatno da će neurolozi uskoro biti zamijenjeni velikim jezičnim modelima; naša otkrića sugeriraju da bi se uskoro mogli naći u liječenju novih, virtualnih pacijenata - modela umjetne inteligencije koji pokazuju kognitivno oštećenje."




























