Može li nam AI pomoći da otkrijemo kad umjetna inteligencija laže?
Veliki jezični modeli kao što su ChatGPT ili Gemini ponekad izmišljaju podatke; treba li onda vatru gasiti vatrom i slične LLM-ove koristiti za otkrivanje ovih pogrešaka?


Veliki jezični modeli kao što su ChatGPT i Gemini sustavi su umjetne inteligencije koji mogu čitati i generirati prirodni ljudski jezik. Međutim, takvi sustavi znaju biti skloni halucinacijama, u kojima je generirani sadržaj netočan ili besmislen. Granice do kojih u svojim halucinacijama ti LLM-ovi mogu ići nije lako otkriti jer se njihovi odgovori doista mogu činiti uvjerljivima.
Detektor konfabulacija
Istraživači Odjela računalnih znanosti Sveučilišta u Oxfordu odlučili su kvantificirati stupanj halucinacija koje stvara LLM. Svoju metodu za otkrivanje halucinacija u velikim jezičnim modelima koja mjeri nesigurnost u značenju generiranih odgovora predstavili su u časopisu Nature.
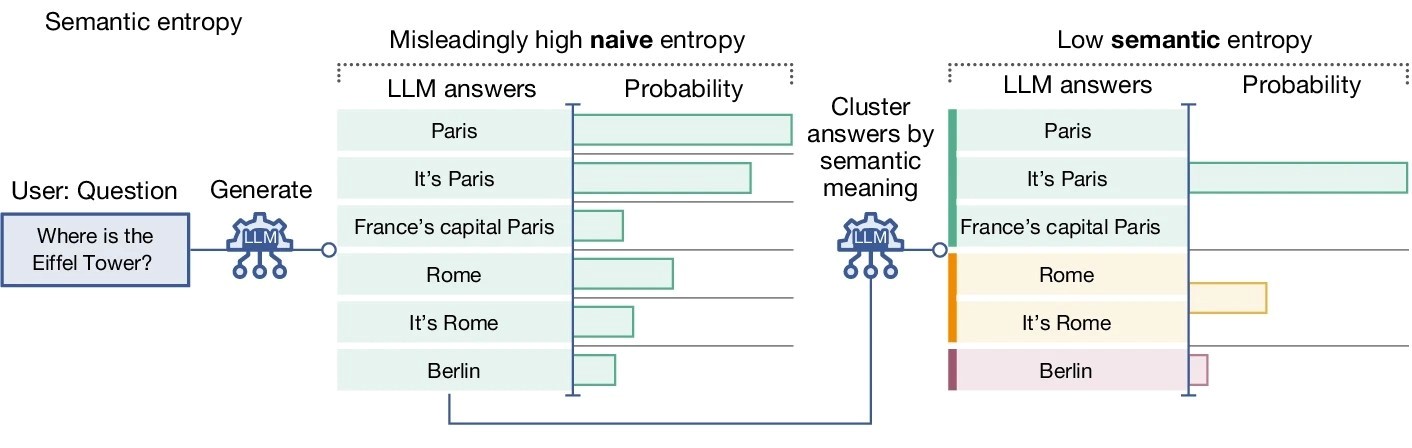
Njihova metoda detektira konfabulacije, specifičnu potklasu proizvoljnih halucinacija koje se javljaju kad u LLM-u postoji nedostatak znanja. Pristup uzima u obzir nijansu jezika i kako se odgovori mogu izraziti na različite načine, s različitim značenjima. Autori su na primjerima pokazali kako njihova metoda može otkriti konfabulacije u biografijama koje je izradio LLM i u odgovorima na pitanja iz općem znanja, znanosti o životu i raznim trivijalnim temama.
Pristrani pristup
Zadatak obavlja LLM, a ocjenjuje ga treći LLM, što je jednako "gašenju vatre vatrom", komentiraju recenzenti ovog rada. Korištenje velikog jezičnog modela za procjenu metode temeljene na LLM-u čini se cirkularnim i moglo bi, kažu, biti pristrano.

Međutim, autori smatraju kako njihova metoda može pomoći korisnicima da razumiju kad bi trebali biti oprezni pri oslanjanju na odgovore velikih jezičnih modela i tako steći više povjerenja u njih.














