Znanstvene časopise preplavljuju lažni tekstovi generirani umjetnom inteligencijom

Dok pravi znanstvenici grizu nokte u iščekivanju recenzija svojih radova, umjetna inteligencija ih bez muke napiše na tisuće – nerijetko posve lažnih i besmislenih… ali uredno objavljenih u relevantnim časopisima
U časopisu iz područja medicinskih znanosti objavljen je članak koji opisuje čudesnu metodu dijagnostike i liječenja, popraćen impresivnim grafikama, zvučnim naslovom i referencama na „ugledne radove“ koje nitko prije nije vidio – jer i ne postoje. Autor članka je izvjesni dr. Chang Shlang iz instituta za kojega se također ispostavi da uopće ne postoji. Metodologija istraživanja koja se opisuje u članku je nesuvisla i konfuzna, a rezultati previše dobri da bi bili istiniti. Povrh svega, ističe se osebujan stil pisanja i rečeničnih konstrukcija: tipičan „robotski“, s prepoznatljivim potpisom umjetne inteligencije.
Fraze koje bole
Ovo nije uvod u zaplet nekog distopijskog romana, već žalosna (ali istinita) nova realnost u akademskom izdavaštvu: znanstveni časopisi preplavljeni su AI-generiranim radovima, od kojih mnogi doslovno nemaju veze s mozgom.
Zahvaljujući istraživačima poput Guillaumea Cabanaca i njegovog tima, otkrivene su na tisuće radova s bizarnim izrazima poput counterfeit consciousness (u značenju artificial intelligence) ili profound neural fabrics (što god to značilo). Ove „jezične nakaze“ plod su generativnih AI-alata koji su trenirani da pišu kao ljudi, ali nerijetko fulaju ceo fudbal, i to spektakularno.
Stručnjaci su te frankenšajnske izraze nazvali tortured phrases – što bismo mogli prevesti kao „silovane fraze“. One zvuče kao da je AI-program čuo za nekakvu „umjetnu inteligenciju“, ali ju je kroz loš Google Translate i tri kruga loše kodiranog algoritma prevela u „krivotvorenu svijest“. A jedino što u svemu tome jeste krivotvoreno jeste pokušaj da se takve tekstove predstavlja kao produkt ljudskog rada, istraživanja i pisanja.
Tko to radi – i zašto?
Odgovor je jednostavan: zato što se isplati.
U nekim mnogoljudnim zemljama s velikim brojem ambicioznih stručnjaka (najčešće se spominju Kina, Iran, Indija…), objavljivanje znanstvenih radova otvara vrata napredovanju u karijeri, promaknućima, dodatnim financijama i višem akademskom statusu. Štancanje znanstvenih radova počinje s pritiskom na akademike, doktore znanosti, pa čak i obične studente, koji su prisiljeni objavljivati radove kako bi opstali u sustavu – stipendije, napredovanja, rangiranja, bodovi – sve se mjeri u broju publikacija.
U toj utrci za objavama, mnogi počinju proizvoditi radove industrijskim tempom, često bez dovoljne znanstvene rigoroznosti. Umjesto da se piše kad se ima što reći, piše se jer se mora. I to svakih šest mjeseci. Ili češće.

Posljedica tog „silovanja znanosti“ je pojava tzv. “paper mills”, svojevrsnih „kovačnica znanstvenih radova“, u kojima ekipa marljivih pubertetlija bilo kome tko plati par stotina dolara (ma, može i u bitcoinima!) sastavi, napiše i pošalje gotov „znanstveni“ rad, uredno potpisan imenom platitelja – i naravno, generiran ChatGPT-om ili Geminijem.
Kovačnice znanstvenih radova funkcioniraju poput onih ekipa gejmerskih klinaca u MMORPG igrama koji danonoćnim "farmanjem" dižu levele likovima – ne zbog igre, nego zbog zarade. Kao što netko kupi takvog „nabildanog“ visoko rangiranog avatara jer nema vremena ni vještine da ga sam izgradi (Elon Musk, anyone?), tako i neki znanstvenici kupuju gotove isfabricirane radove kako bi skratili ili posve preskočili skup i mukotrpan put pravog znanstvenog istraživanja.
Brak iz računa, ali bez savjesti
Kad algoritmi generiraju tekstove, a ljudi pred time zatvaraju oči, nastaje savršena kombinacija za akademske prevare: na scenu stupaju tzv. predatorski časopisi – platforme koje nemaju pretjerano visoke standarde za objavu, ali zato imaju visoke naknade. Oni ne traže znanstvenu izvrsnost nego broj kartica i broj kreditne kartice. Sve dok autor plati, sve je objavljivo. Recenzenti? Ponekad su izmišljeni. Recenzije? Ponekad stignu isti dan. Ukratko, izdavaštvo u kojem je jedina recenzija – uplata. I tako je zatvoren krug pohlepe za novcem i znanstvenim statusom, unutar kojega prava znanost nema šanse za preživljavanjem.
U cijeli proces sada se umiješala i umjetna inteligencija. Uz pomoć LLM sustava, danas je moguće generirati članak koji izgleda, zvuči i diše kao znanstveni. Ima apstrakt, metode, rezultate, zaključak – sve ono što bi čak i pažljiviji čitatelj prepoznao kao „rad“. No ispod sjajnog omota često se krije... ništa. Ili još gore – nasumična kombinacija već postojećih radova, bez ikakvog značenja, validnosti, pa ni istinitosti. I takvi se radovi, zahvaljujući niskim kriterijima predatorskih časopisa, objavljuju. Brzo. I masovno.
No, taj problem ne pogađa samo opskurne „štancerske“ časopise: sve češće se može naići na primjere da se i u nekima od ozbiljnih i visoko indeksiranih publikacija također objavilo radove sumnjive originalnosti, sadržaja i autorstva. Sustavi recenzije i u najboljim časopisima jednostavno nisu dovoljno pripremljeni za tsunami tekstova koje pišu jezični modeli, a ne ljudi.
Učenje na (ne)postojećim radovima: AI jede vlastiti izmet
A tu dolazimo do najopasnijeg dijela ciklusa: kad se takvi radovi, koji su smeće, počnu koristiti kao izvor podataka za treniranje budućih modela umjetne inteligencije. Drugim riječima, AI modeli uče znanost iz članaka koje je već napisao AI. Učinak je sličan kao kad papiga nauči ponavljati gluposti s YouTubea, pa drugu papigu podučava tim glupostima. Nisu ni ljudi imuni – drugi znanstvenici, studenti i novinari ponekad citiraju ove radove misleći da je riječ o pravoj literaturi. Tako se znanstveno smeće širi, umnaža, i zagađuje bazu znanja na kojoj bismo svi trebali graditi nešto korisno.
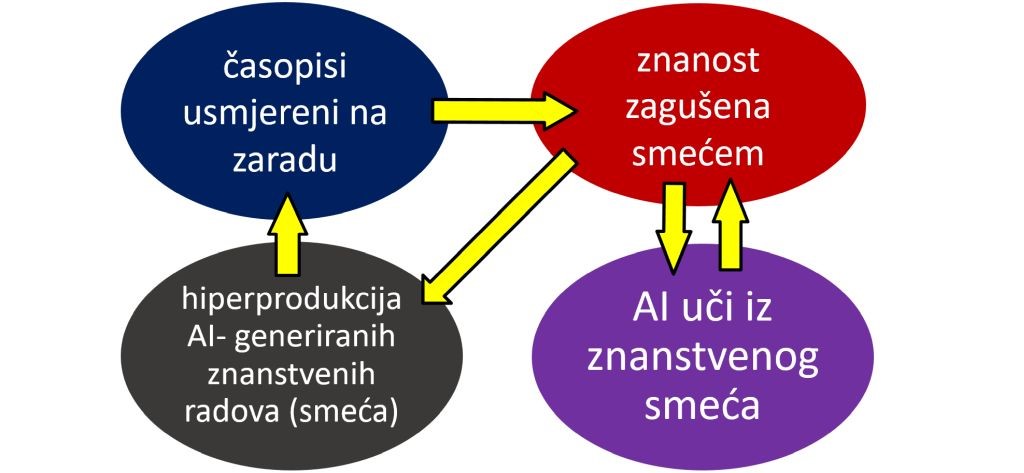
Rezultat? Spirala autokanibalizma: AI piše bezvrijedne članke, oni se objavljuju u časopisima bez kriterija, drugi AI sustavi ih gutaju kao znanstvene istine, i ponovno izbacuju novi val – još sofisticiranijeg – znanstvenog smeća.
Kao da kopiramo vlastite pogreške – ali svaki put u sve lošijoj rezoluciji. Posljedice toga se nesagledive… ili, što je još tragičnije – sasvim sagledive: medicinske smjernice će biti kompromitirane, a povjerenje javnosti nepovratno narušeno.
Znanstveni smog
U jednom zapaženom primjeru, analiza iz sada već daleke 2021. godine otkrila je na stotine radova s AI-generiranim „silovanim frazama“ na mrežama Scopus i Web of Science, poznatim i priznatim mjestima gdje se nalaze ozbiljni radovi objavljeni u cijenjenim časopisima.
Premda se znanstveni svijet trudi reagirati, pa od samih početaka postoje pokušaji da se stane na kraj toj praksi masovnog „štancanja“ neznanstvenog AI-smeća, evidentno je da većina metoda borbe protiv krivotvorenja sadržaja i autorstva nije baš uspješna: jednostavno, AI može pisati brže i više nego što ljudi-recenzenti mogu čitati.
Ova pojava stvara tzv. znanstveni smog – situaciju da je na znanstvenim mrežama i u časopisima u sve većoj gomili neznanstvenog smeća sve teže pronaći nešto što je zaista vrijedno. Meta-analize, vrsta istraživanja kod kojega se podaci prikupljaju iz više izvora (istraživanja, analiza, studija…) radi usporedbi i donošenja zajedničkog zaključka, mogu „pokupiti“ i takve lažne radove, te donijeti pogrešne zaključke.
Znanost bi trebala biti alat za razumijevanje svijeta, no ovakvom zlouporabom umjetne inteligencije sve više postaje - smetlište. Današnji znanstveni krajolik sve više nalikuje traci u tvornici jeftinih suvenira – samo što umjesto figurica iz Kine ili Tajvana dobivamo „znanstvene“ članke, ponekad i stotine njih dnevno.
Yoda i Shakespeare
Naravno, sâma AI bi mogla pomoći u detekciji takvih radova, pa se već razvijaju algoritmi za prepoznavanje generičkog jezika, plagijata, pa i „silovanih fraza“. Ali, situacija „na znanstvenom terenu“ i dalje nalikuje kontinuiranoj bitki proizvođača antivirusnog softvera s programerima koji svakodnevno smišljaju novije, naprednije i masovnije hackove, pa znanstveni urednici ozbiljnih časopisa sve više imaju osjećaj da kod recenziranja pristiglih znanstvenih radova hodaju po minskom polju s povezom preko očiju.

Dok (i ako) se softverska detekcija AI-generiranih znanstvenih tekstove ne usavrši do razine kojom će se pseudo-znanstveni AI-bullshit uspješno i brzo prepoznavati i eliminirati iz znanstvenih komunikacijskih mreža, za početak bi znanstveno izdavaštvo trebalo koristiti nekoliko sigurnosnih točaka:
- transparentnost – autori bi morali navesti je li korišten AI alat (kao što to već zahtijevaju neki časopisi)
- obuka recenzenata – kako bi znali prepoznati AI-tekstove: ako fraze zvuče kao timska suradnja Shakespearea, tehničkog priručnika i master-Yode, nešto bi trebalo biti sumnjivo
- etika – akademske institucije trebaju jasno regulirati upotrebu AI-ja u znanstvenom pisanju
- javna svijest – ako vjerujemo svemu što je „objavljeno u časopisu“, uskoro ćemo piti čaj od uranija i liječiti karcinome kremom od laserskog jogurta.
Hoće li znanost preživjeti umjetnu inteligenciju?
Naravno da hoće. Ali ne bez žestoke borbe. Umjetna inteligencija je samo alat (s kojim treba znati vješto i korisno rukovati): može u velikoj mjeri olakšati istraživanje i pomoći formuliranju i oblikovanju zaključaka i gotovih tekstova znanstvenih radova, ali može i ozbiljno naškoditi znanosti. Pisanje znanstvenog rada nije samo tipkanje riječi: to je razumijevanje problema, interpretacija rezultata, a iznad svega - odgovornost prema zajednici.
AI možemo naučiti da sastavi poglavlje ili cijeli znanstveni rad, ali ga (još uvijek) ne možemo naučiti etici, autocenzuri i znanstvenoj savjesti. A dok se to ne dogodi – pazite što čitate, jer možda to nije pisao čovjek, nego stroj koji nije sposoban shvatiti posljedice svojeg besmislenog konstruiranja činjenica.















