Na MIT-u osmislili učinkovit protokol za zaštitu korisničkih podataka
Novi protokol štiti osobne podatke i istovremeno osigurava točnost rezultata preporuka, a toliko je učinkovit da se može pokrenuti na pametnom telefonu preko vrlo spore mreže


Algoritmi nam preporučuju proizvode koje kupujemo online i predlažu pjesme koje bi nam se mogle svidjeti dok streamamo glazbu. No, ovi algoritmi koriste naše osobne podatke poput prošle kupnje ili povijesti pregledavanja. Osjetljiva priroda takvih podataka otežava čuvanje privatnosti, a postojeće metode zaštite oslanjaju se na teške kriptografske alate koji zahtijevaju ogromne količine računanja i propusnosti.
Štiti i osigurava
Istraživači MIT-a nude bolje rješenje; razvili su protokol za očuvanje privatnosti koji je toliko učinkovit da se može pokrenuti na pametnom telefonu preko vrlo spore mreže. On štiti osobne podatke i istovremeno osigurava točnost rezultata preporuka. Uz to, ovaj protokol minimizira neovlašteni prijenos informacija iz baze podataka, čak i kad zlonamjerni agent pokuša prevariti bazu podataka kako bi otkrio tajne podatke.
Novi protokol mogao bi biti posebno koristan u situacijama u kojima bi curenje podataka moglo narušiti zakone o privatnosti korisnika. Pritom su na umu posebno imali situacije s manipulacijom povijestima bolesti ili ciljanim oglasima.
U izradi protokola, istraživači MIT-ovog Laboratorija za računalne znanosti i umjetnu inteligenciju (CSAIL) oslonili su se na niz kriptografskih i algoritamskih trikova, a rad će predstaviti na IEEE simpoziju o sigurnosti i privatnosti.
Podaci u susjedstvu
Protokol se oslanja na dva odvojena poslužitelja koji pristupaju istoj bazi podataka. Korištenje dva poslužitelja čini proces učinkovitijim i omogućuje korištenje kriptografske tehnike pronalaženja privatnih informacija. Ova tehnika omogućuje klijentu da upita bazu podataka bez otkrivanja što traži, objašnjavaju istraživači.
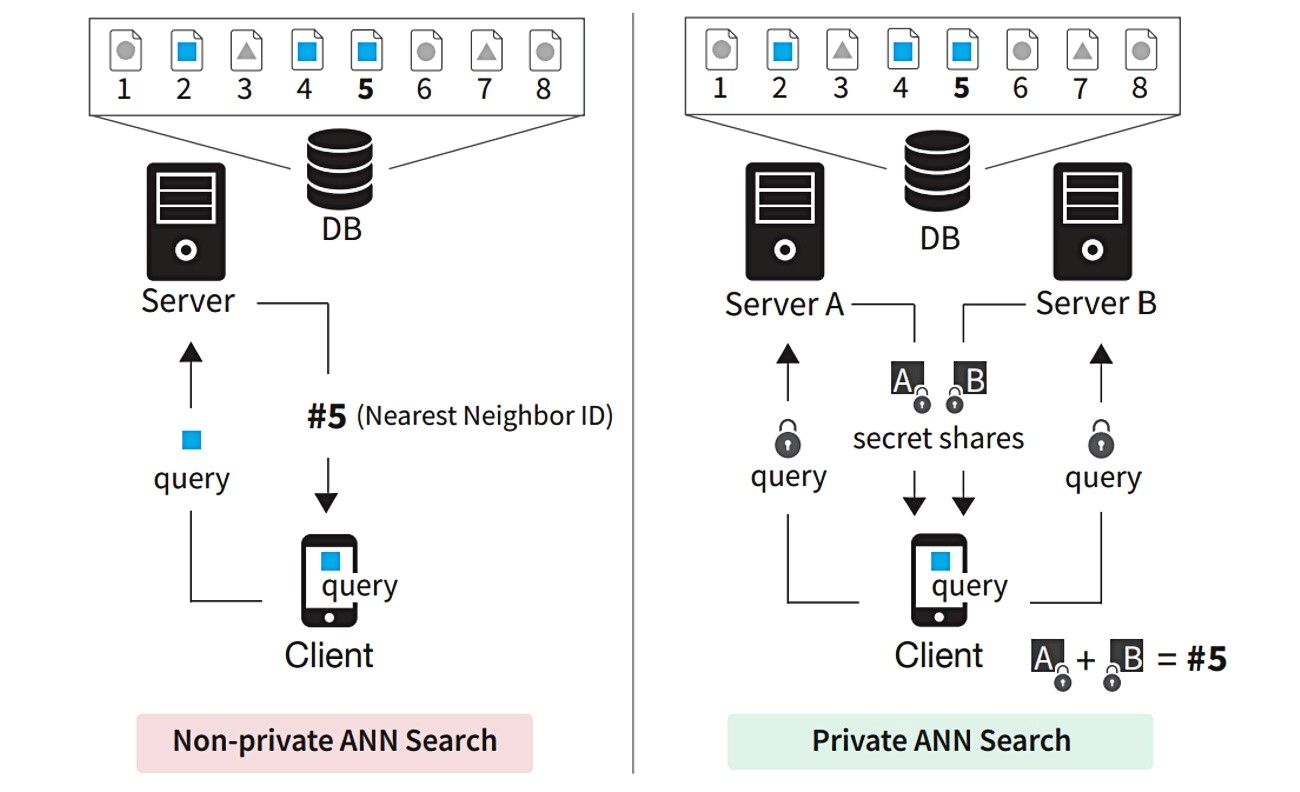
Istraživači su upotrijebili tehniku ugađanja koja eliminira mnoge dodatne vektore na prvom mjestu, a zatim su upotrijebili drugačiji trik, oblivious masking, kako bi sakrili sve dodatne točke podataka osim stvarnog najbližeg susjeda. Time se učinkovito čuva privatnost baze podataka, tako da klijent neće naučiti ništa o vektorima značajki u bazi podataka.
Sekunde za obradu
Ovaj proces zahtijeva nekoliko sekundi obrade po upitu i manje od 10 megabajta komunikacije između klijenta i poslužitelja, čak i s bazama podataka koje su sadržavale više od 10 milijuna stavki. Druge sigurne metode mogu zahtijevati gigabajte komunikacije ili sate računalnog vremena.
Sa svakim upitom, njihova je metoda postigla točnost veću od 95 posto, što znači da je gotovo svaki put pronašla stvarnog približnog najbližeg susjeda točki upita.
Dva entiteta
Tehnike koje su koristili za omogućavanje privatnosti baze podataka spriječit će zlonamjernog klijenta, čak i ako pošalje lažne upite. Istraživači žele prilagoditi protokol tako da može sačuvati privatnost koristeći samo jedan server. To bi moglo olakšati njegovu primjenu jer upravljanje bazom podataka ne bi zahtijevalo korištenje dva entiteta koji međusobno ne dijele informacije.














