Microsoftov sustav VALL-E iz tri sekunde govora može sintetizirati bilo čiji glas
Ono što je DALL-E za slike, VALL-E bi trebao biti za ljudski glas. Novi sustav jezičnog modeliranja i računalne sinteze glasa treba samo tri sekunde uzorka kako bi uspješno imitirao bilo koga


Microsoft je odlučio mnogo toga uložiti u umjetnu inteligenciju i njezin razvoj u nadolazećim godinama. Već sada znamo da su najveći pojedinačni investitor u OpenAI. U organizaciju koja je izradila ChatGPT i DALL-E do sada su uložili milijardu dolara. Ona trenutačno vrijedi, prema nekim procjenama, 29 milijardi dolara, a Microsoft je u dogovorima da uloži dodatnih 10 milijardi i preuzme 49% vlasničkog udjela u kompaniji koja ima potencijal redefinirati budućnost umjetne inteligencije (i ne samo nje).
Deepfake za glas
Nova tehnologija koja se "kuha" u Microsoftu sada se tiče unaprjeđenja modela "text-to-speech", onih koji iz napisanog teksta sintetiziraju prirodni ljudski glas (vidi: Gabrijela i Srećko). No, njihovi su stručnjaci otišli korak dalje od generiranja sintetičkog ljudskog glasa, pa su uspjeli istrenirati umjetnu inteligenciju da im stvara realistične replike glasova stvarnih ljudi.
Sustav VALL-E, izrađen u Microsoftu i prikazan tek kroz nekoliko demo primjera, koristi napredne računalne neuronske mreže za analizu teksta kroz jezične modele. U to potom kombinira primjere zvučnih zapisa na temelju kojih može generirati nove zvukove. Sustav je treniran na 60 tisuća sati govora oko 7 tisuća različitih govornika na engleskom jeziku, za što kažu da je više stotina puta veći podatkovni skup od onih korištenih na dosadašnjim sličnim sustavima.
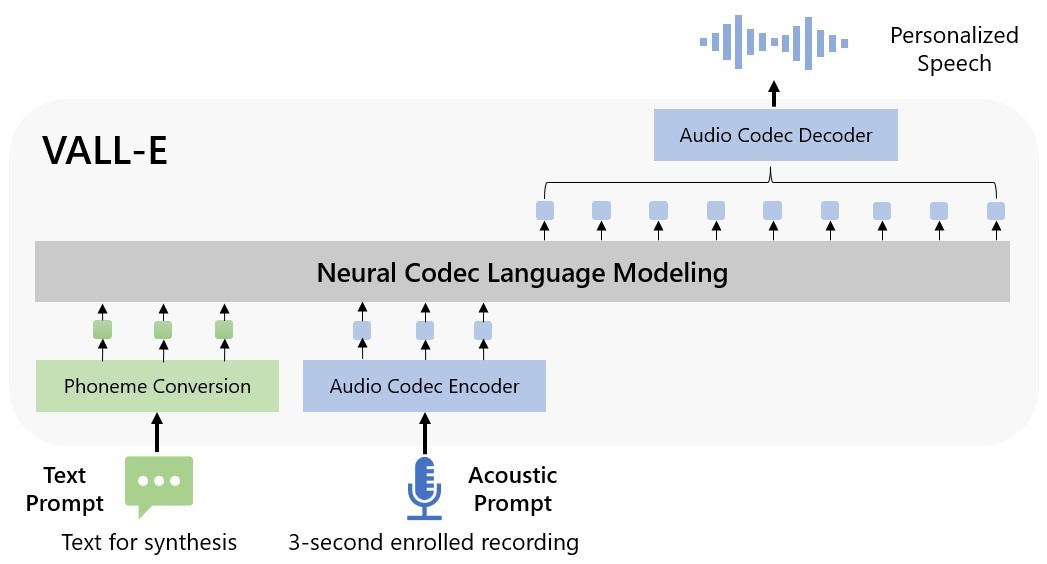
Krajnji rezultat – VALL-E treba "čuti" samo tri sekunde nečijeg govora, da bi glas te osobe uspješno iskoristio za daljnje generiranje zvuka, "govoreći" glasom te osobe. Dodatnu prednost pred postojećim modelima ovaj sustav donosi i zadržavanjem potrebne emocije u glasu, čak i naglaska te zvučnog okruženja, kakvo je "čuo" u tri sekunde uzorka.
Fascinantan, ali i opasan
Na stranicama, na kojima su sustav i prateći rad predstavljeni, može se naći određeni broj primjera sintetiziranog glasa, kao i uzoraka na temelju kojih su nastali. Kao i ChatGPT ili DALL-E, i ova tehnologija već sada fascinira svojom izvedbom i realističnošću konačnog rezultata.
Autori VALL-E-ja na kraju napominju da shvaćaju etičke implikacije računalnog programa koji je u stanju vjerno replicirati bilo čiji glas. Veliki su rizici povezani s mogućim neželjenim korištenjem – od kreiranja deepfake sadržaja, preko varanja sustava za autentifikaciju glasom, pa do najobičnijeg lažnog predstavljanja vjernim oponašanjem. Sustav stoga nije otvoren za javno korištenje, a prije eventualnog puštanja u javnost, potrebno je osigurati da govornik, čiji glas se uzima kao uzorak, bude svjestan toga i da može dati potrebnu privolu za daljnje računalno sintetiziranje vlastitog glasa.














