Novi test za procjenu naprednih AI sustava: "Posljednji ispit čovječanstva"
Centar za sigurnost umjetne inteligencije (CAIS), neprofitna istraživačka organizacija i Scale AI, tehnološka kompanija, predstavili su novo mjerilo za evaluaciju najsuvremenijih AI modela pod nazivom "Posljednji ispit čovječanstva" (Humanity's Last Exam - HLE)...

Današnji testovi za provjeru razine razvijenosti umjetne inteligencije više nisu dovoljno učinkoviti jer vodeći AI sustavi poput onih koje razvijaju OpenAI, Google i Anthropic bez problema rješavaju i najsloženije znanstvene zadatke. Zbog toga je postalo jasno da trebaju preciznije metode kojima bi se mogao pratiti njihov ubrzani razvoj. Kao odgovor pokrenut je projekt pod nazivom "Posljednji ispit čovječanstva" (Humanity's Last Exam - HLE) koji uvodi novi, detaljniji način provjere AI sustava kroz niz različitih znanstvenih područja.
Ispit za AI sadrži oko 3000 pitanja
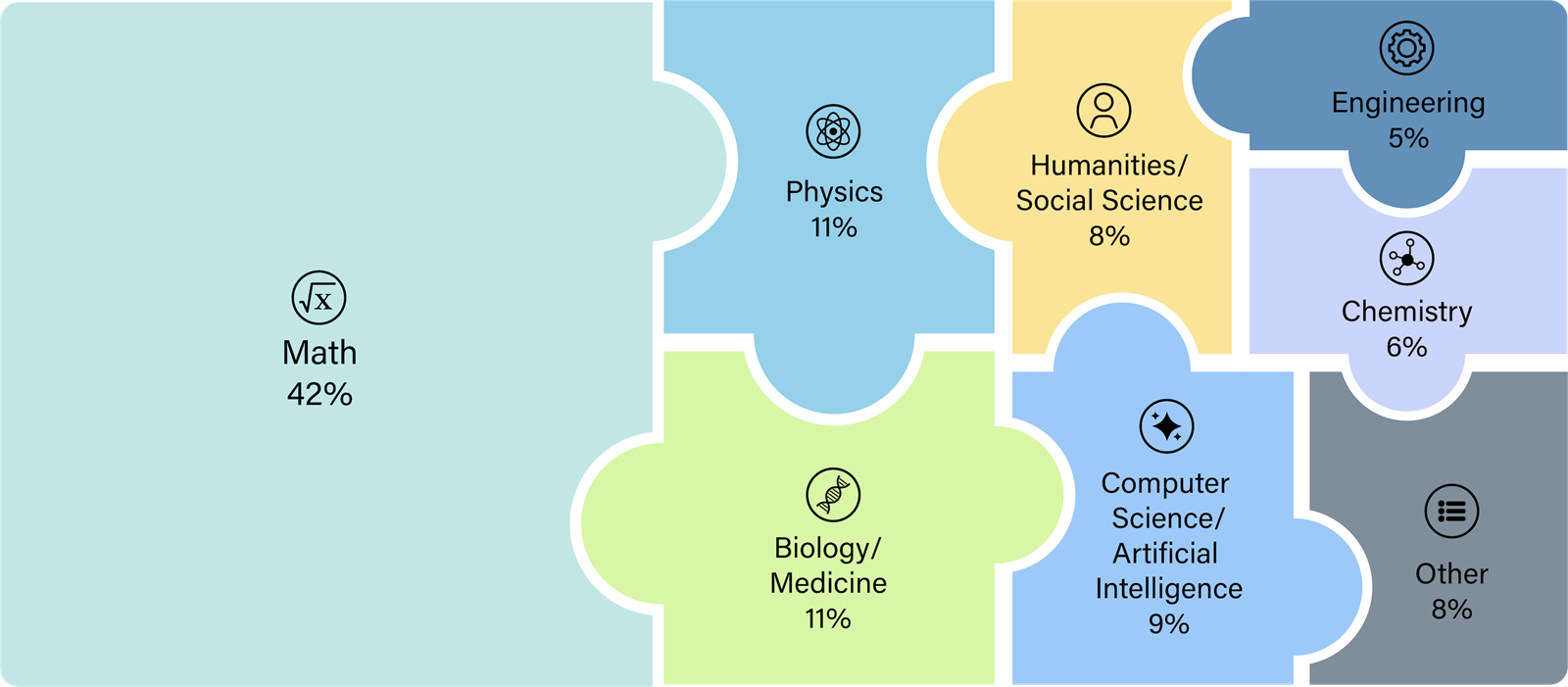
Sam ispit sadrži oko 3000 pitanja s višestrukim izborom i pitanja koja zahtijevaju kratke odgovore. Područja koja pokriva protežu se od analitičke filozofije do raketnog inženjerstva, a pitanja su pomno odabrana kako bi se ispitale granice AI sustava u znanju i logičkom zaključivanju.
HLE se izdvaja od dosadašnjih mjerila jer kombinira tekstualne i multimodalne zadatke. Potonji uključuju slike i dijagrame kojima se testira sposobnost AI sustava da istovremeno obrađuju i tumače vizualne i tekstualne podatke, što omogućuje sveobuhvatniju procjenu njihovih mogućnosti.
Počelo se sa 70.000 probnih pitanja
Razvoj HLE-a odvijao se kroz nekoliko faza. U početku je prikupljeno više od 70.000 probnih pitanja, koja su zatim svedena na 13.000 za stručnu recenziju. Nakon toga je odabrano 3000 konačnih pitanja koja su dodatno dorađena kako bi zadovoljila stroge kriterije za uključivanje u ispit. Istraživači naglašavaju da je HLE zamišljen kao dinamično mjerilo koje će se razvijati usporedno s napretkom umjetne inteligencije. Tim planira kontinuirano usavršavati ispit i istraživati nove metode evaluacije kako bi držali korak s brzim razvojem AI tehnologije.
Dosad AI sustavi padaju na ispitima
Ispit je već proveden na nekoliko vodećih AI modela, uključujući OpenAI-jev GPT-4o i o1, Anthropicov Claude 3.5 Sonnet te Googleov Gemini 1.5 Pro. Prvi rezultati pokazuju da čak i najnapredniji AI sustavi imaju značajnih poteškoća s ispitom - model s najboljim rezultatom postigao je točnost od samo 9,1%. Ovakav rezultat jasno ukazuje na još uvijek postojeće izazove u razvoju AI sustava koji bi trebali biti sposobni za stručno zaključivanje u različitim područjima znanja.






















