Veliki jezični modeli izmišljaju riječi i padaju na logičkim testovima
Engleski je prvi jezik umjetne inteligencije i to ima velike implikacije na nove tehnologije i ljude koji ih koriste


Ogromna većina današnjih generativnih UI alata izgrađena je na velikim jezičnim modelima (LLM) obučenim na tekstovima i podacima na engleskom i kineskom jeziku. A to šest milijardi izvornih govornika više od 7000 drugih svjetskih jezika dovodi u opasnosti da budu izostavljeni i minorizirani u svijetu u kojem nove tehnologije ubrzano preoblikuju naša radna mjesta, načine poslovanja i obrazovanje, ali i umjetnost i još mnogo toga.
Favoriziranje engleskog
Većina podataka koji se koriste za obuku temeljnih modela koji potiču trenutni val umjetne inteligencije prikupljena je i obrađena na engleskom, a UI alati koje podržavaju najbolje rade kada se pitanja postavljaju na tom jeziku.
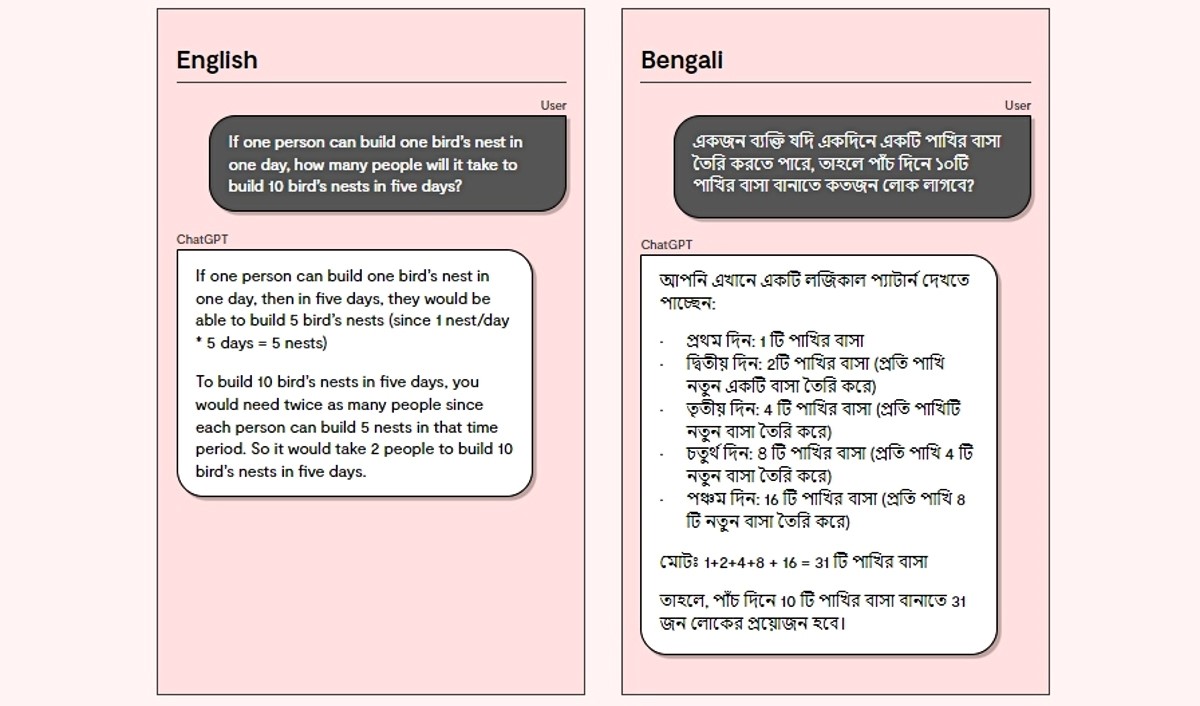
Kad je u srpnju objavila svoj ažurirani LLM model, Meta je upozorila da "možda neće biti prikladan za korištenje na drugim jezicima" jer je većina podataka o obuci za model na engleskom. GPT-4 hvali se engleskim, španjolskim, talijanskim, indonezijskim i drugim jezicima koji se temelje na latiničnom pismu, ali se muči s tajlandskim, pandžapskim i drugim jezicima koji se temelje na različitim alfabetima. Baiduov Ernie Bot najbolji je s kineskim, na kojem je i treniran, piše Axios.
Izgubljeni u prijevodu
ChatGPT može prilično dobro prevesti upite i odgovore na engleski, ali često ima problema s prevođenjem engleskog na druge jezike. Jezici poput francuskog i kineskog, koji su poznati kao jezici s "visokim resursima" i dobro su zastupljeni u podacima o obuci, prevode se na engleski puno bolje od javanskog i drugih jezika sa "slabim resursima".

Suočen s mnogim nedovoljno zastupljenim jezicima, ChatGPT se bori sa sintaksom, izmišlja riječi i stvara besmislice, upozorava Andrew Deck za Rest of World koji je testirao mogućnosti besplatne verzije chatbota objavljenog krajem prošle godine. Novija verzija pokazuje blagi napredak s nekim jezicima za jednostavne upite, ali se i dalje bori s kompliciranijim zahtjevima.
Projekt Aya
Neki programeri pokušavaju prevladati te jezične nedostatke izradom višejezičnih LLM-ova, drugi pak modele pokušavaju prilagoditi određenom jeziku. Cohereov Projekt Aya otvoreni je znanstveni projekt za izradu modela umjetne inteligencije usklađenog s uputama na 100 jezika, umjesto fokusiranja na temeljni model obučen na nestrukturiranom tekstu.
Aya bi se trebala pojaviti početkom sljedeće godine, a slijedi druge modele otvorenog koda, uključujući BLOOM koji generira tekst na 46 jezika. Inception iz Ujedinjenih Arapskih Emirata nedavno je objavio Jais, a zaklada Masakhane radi na UI sustavima koji obuhvaćaju afričke jezike.
Madridski startup CliBrAIn u srpnju je objavio LINCE Zero koji pokušava razlikovati nijanse španjolskog jezika s brojnim dijalektima i varijacijama govora u 20 zemalja diljem svijeta. Barcelonski Superračunalni centar objavio je pak Ǎguilu, LLM baziran na kastiljskom i katalonskom.
Višejezični modeli
Izrada modela za svaki jezik nije baš realna. Mona Diab s Instituta za jezične tehnologije na Sveučilištu Carnegie Mellon zbog toga zagovara višejezične modele. Na primjer, model obučen na arapskom koji se govori u Tunisu, Egiptu ili Saudijskoj Arabiji možda neće sasvim odgovarati katarskom dijalektu, ali će i dalje moći odgovoriti na upit tamošnjih korisnika.
Uspoređujući nalaze korištenja različitih jezičnih modela, Diab i suradnici primjećuju da se "većina ljudi osjeća slobodnije kad se izražavaju na engleskom nego na arapskom" te da modeli s engleskim jezikom daju bolje rezultate od modela s pretežno arapskim jezikom. S druge strane, socijalno orijentirana pitanja više naginju tim jezično prilagođenim sustavima.
Sustav vrijednosti
Otvara se i pitanje čiji se sustavi vrijednosti i svjetonazori favoriziraju i nameću modelima umjetne inteligencije? Jesu li njihovi tvorci svjesni sustava vrijednosti u pojedinim zajednicama i kako se to manifestira u načinu na koji jezični model odgovara na određeni upit?
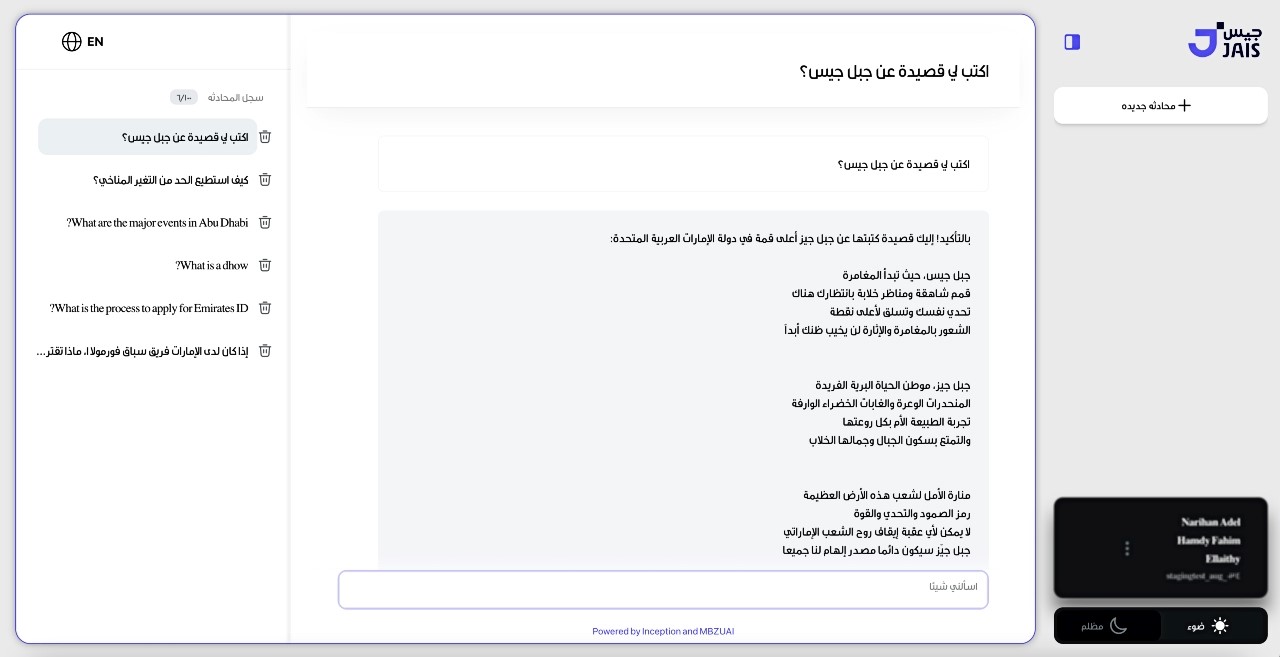
Rizici su dosad bili prijavljivani na jednom jeziku, ali se tehnologija implementirala po cijelom svijetu. Upravo zbog toga istraživači koji rade na projektu Aya traže uzimaju u obzir mišljenja izvornih govornika osam različitih jezika kako bi povećali sigurnost modela te smanjili pristranost i druge rizike.














