Umjetna inteligencija koja radi s pravom dozom znatiželje
Istraživači MIT-a učinili su veliki iskorak u rješavanju problema balansiranja između radoznalosti i iskorištavanja u podržanom učenju


Znatiželja pokreće umjetnu inteligenciju da istražuje svijet. Strojevi, u nekim slučajevima, koriste podržano učenje (reinforcement learning) u kojem UI agent uči tako što je nagrađuju za dobro ponašanje i kažnjavaju za loše. Ovi se agenti bore s balansiranjem vremena provedenog u otkrivanju boljih radnji i vremena provedenog u poduzimanju radnji koje su dovele do visokih nagrada.
Prava doza znatiželje
Previše znatiželje može odvratiti agenta od donošenja dobrih odluka, dok premalo znači da nikad neće otkriti dobre odluke.
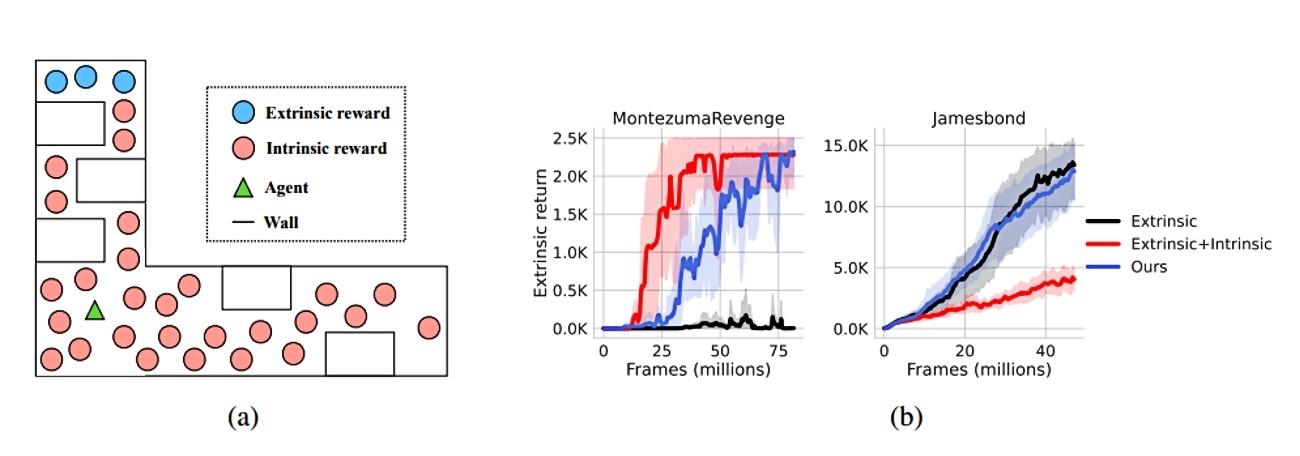
U potrazi za UI agentom s pravom dozom znatiželje, istraživači iz MIT-ovog Laboratorija za računalnu znanost i umjetnu inteligenciju (CSAIL) izradili su algoritam koji prevladava problem pretjerano znatiželjne umjetne inteligencije. Njihov algoritam automatski povećava znatiželju kada je to potrebno i potiskuje kad agent dobije dovoljno nadzora okoline da zna što mu je činiti.
Testiranje igara
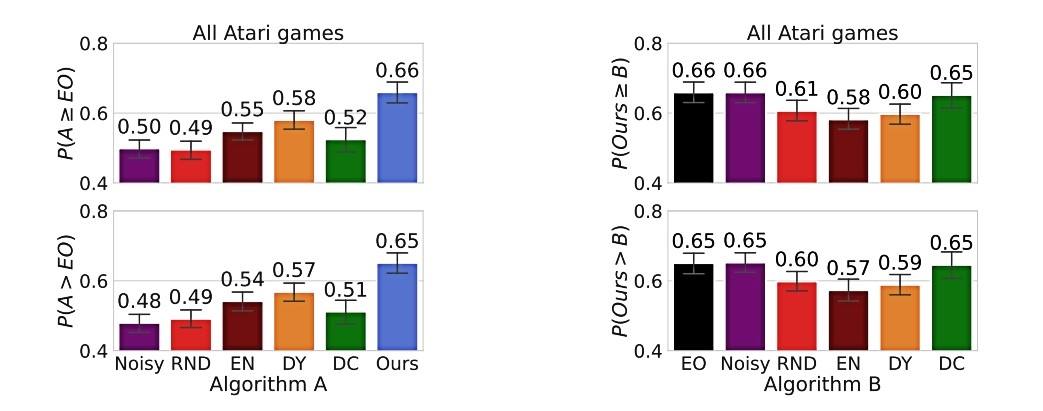
Nakon testiranja na više od 60 videoigara, algoritam je bio uspješan i u teškim i u lakim zadacima istraživanja, dok su prethodni algoritmi mogli rješavati samo teške ili lake domene. Ovom metodom UI agenti koriste manje podataka za učenje pravila donošenja odluka.

"Ako dobro svladate kompromis između istraživanja i eksploatacije, možete brže naučiti ispravna pravila donošenja odluka; sve manje zahtijeva mnogo podataka, što pak znači neoptimalne medicinske tretmane, manji profit za web stranice i robote koji ne mogu naučiti činiti pravu stvar", objašnjavaju istraživači.
Dvije skupine
U eksperimentima istraživači su igre kao što su "Mario Kart" i "Montezuma's Revenge" podijelili u dvije različite skupine: jednu u kojoj je nadzor bio rijedak i drugu u kojoj je nadzor bio veći.
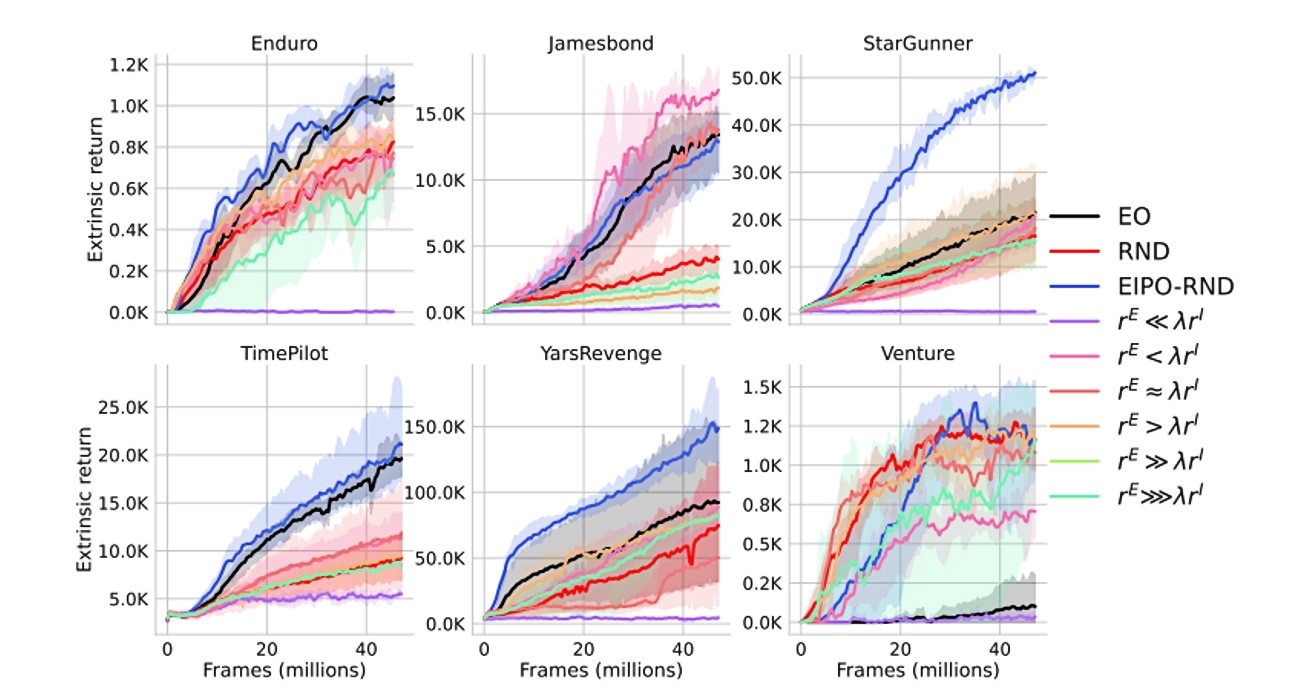
Algoritmi koji potiču znatiželju dobro se snalaze u scenariju u kojem se iz igre uklone sve nagrade i agentu tek na kraju priopćava koliko je dobro prošao. U slučaju kad agentu osigurate gust nadzor i niz nagrada za preskakanje cijevi, skupljanje novčića i eliminiranje neprijatelja bolje se snalazi algoritam bez znatiželje jer često biva nagrađen. Znatiželjni algoritam uči sporo jer čini niz stvari koje su zanimljive, ali ne pomaže agentu da uspije u igri.
Matematička definicija znatiželje
Međutim, timski algoritam dosljedno je dobro funkcionirao, bez obzira na okruženje u kojem se nalazio. Na MIT-u se sad žele posvetiti istraživanju prikladne metrike jer znatiželju još nitko dosad nije uspio matematički definirati.

"Postizanje dosljedno dobrih performansi na novom problemu iznimno je izazovno. Poboljšavanjem algoritama istraživanja možemo uštedjeti trud na podešavanju algoritma", kažu istraživači koji predlažu algoritam koji podešava ravnotežu između istraživanja i eksploatacije. A njihov algoritam doista ubrzava stvari: umjesto da se problem rješavao tjedan dana, sad se zadovoljavajući rezultati mogu dobiti za nekoliko sati.
Veliki izazov
"Jedan od najvećih izazova za trenutačnu umjetnu inteligenciju i kognitivnu znanost je kako uravnotežiti istraživanje i iskorištavanje; potraga za informacijama nasuprot potrage za nagradom. Djeca to rade besprijekorno, ali je računski izazovno", objašnjavaju istraživači.
Njihov rad koristi impresivne nove tehnike da to postigne automatski, dizajnirajući agenta koji može sustavno uravnotežiti znatiželju o svijetu i želju za nagradom. Bit će zanimljivo vidjeti što će se dogoditi kad se takve metode počnu širiti s igara na robotske agente u stvarnom svijetu.






















