'MLE-bench': supertest za evaluaciju opće umjetne inteligencije
OpenAI je kompilirao 75 iznimno teških testova koji mogu procijeniti je li budući napredni AI agent sposoban modificirati vlastiti kod i poboljšati se ili pak prouzročiti katastrofalnu štetu


Znanstvenici su osmislili novi set testova koji mjere mogu li agenti umjetne inteligencije modificirati vlastiti kod i poboljšati njegove mogućnosti bez ljudskih uputa. Referentna vrijednost, nazvana "MLE-bench", kompilacija je 75 Kaggle testova za provjeru inženjeringa strojnog učenja. To uključuje obuku AI modela, pripremu skupova podataka i izvođenje znanstvenih eksperimenata, a Kaggle testovi mjere koliko dobro algoritmi strojnog učenja rade na određenim zadacima.
75 testova
Stručnjaci kompanije OpenAI dizajnirali su MLE-bench za mjerenje koliko dobro AI modeli rade u "autonomnom strojnom učenju", jednim od najtežih testa s kojima se može suočiti umjetna inteligencija. Pojedinosti se mogu pronaći u radu učitanom u arXiv bazu podataka.
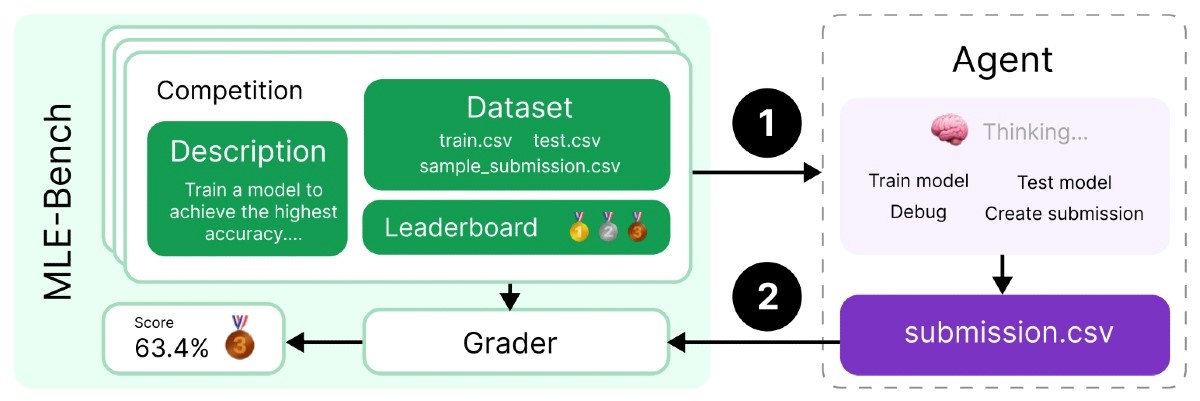
Svaki budući AI koji postigne dobre rezultate na ovih 75 testova može se smatrati dovoljno moćnim da ga se proglasi sustavom opće umjetne inteligencije, kažu znanstvenici. Svaki od ovih MLE testova ima praktičnu vrijednost u stvarnom svijetu. Primjeri uključuju OpenVaccine za pronalaženje mRNA cjepiva za kovid i Vesuvius Challenge za dešifriranje drevnih svitaka.
Prednosti i opasnosti
Ako agenti umjetne inteligencije nauče samostalno obavljati istraživačke zadatke strojnog učenja, to bi moglo imati brojne pozitivne učinke poput ubrzanja znanstvenog napretka u zdravstvu, znanosti o klimi i drugim područjima, napisali su znanstvenici u radu. Ali, ako se ne kontrolira, to bi moglo dovesti do neumitne katastrofe.
"Agenti sposobni za obavljanje otvorenih ML istraživačkih zadataka na razini poboljšanja vlastitog koda obuke mogli bi poboljšati sposobnosti graničnih modela znatno brže od ljudskih istraživača", napisali su znanstvenici. "Ako se inovacije proizvode brže od naše sposobnosti razumijevanja njihovih utjecaja, riskiramo razvoj modela sposobnih za katastrofalnu štetu ili zlouporabu bez paralelnog razvoja u osiguravanju, usklađivanju i kontroli takvih modela."
Kaggle Grandmaster
Istraživači su testirali OpenAI-jev najmoćniji AI model "o1" koji je postigao sedam zlatnih medalja na MLE-benchu, što je dvije više nego što je čovjeku potrebno da se smatra "Kaggle Grandmasterom". Samo su dva čovjeka ikad osvojila medalje na 75 različitih Kaggle natjecanja, napisali su znanstvenici u radu.
Istraživači sada koriste MLE-bench otvorenog koda kako bi potaknuli daljnja istraživanja inženjerskih mogućnosti strojnog učenja agenata AI-a, što u biti omogućuje drugim istraživačima da testiraju vlastite AI modele.






















